NSI Première
Un ordinateur ne manipule en fin de compte que des bits (0 ou 1). Or, nous écrivons avec des lettres et des signes de ponctuations. Comment faire la correspondance entre la suite de 0 et de 1 manipulée par l'ordinateur et le texte tel qu'il a été écrit ?
En télécommunications et en informatique, un jeu de caractères codés (charset encoding en anglais) est un code qui associe un jeu de caractères d’un alphabet avec une représentation numérique pour chaque caractère de ce jeu. Le jeu de caractère est nommé charset (character set) et le code qui relie chaque caractère à un nombre est nommé encoding.
Par exemple, le code Morse (qui associe l’alphabet latin à une série de pressions longues et de pressions courtes sur le manipulateur morse du télégraphe) est un des premier jeux de caractères codés.Le code ASCII (on prononce [askiː]) s’est imposé au début de l’ère informatique pour coder 128 lettres, chiffres et autres symboles.
Le code ASCII (American Standard Code for Information Interchange) permet de coder les caractères les plus utilisés en langue anglaise : les lettres de l’alphabet en majuscule (de A à Z) et en minuscule (de a à z), les dix chiffres arabes (de 0 à 9), des signes de ponctuation (point, virgule, point-virgule, deux points, points d’exclamation et d’interrogation, apostrophe ou quote, guillemet, parenthèses, crochets etc.), quelques symboles et certains caractères spéciaux invisibles (espace, retour-chariot, tabulation, retour-arrière, etc.).
Les créateurs de ce code limitèrent le nombre de ses caractères à 128, c’est-à-dire 27 , pour qu’ils puissent être codés avec seulement 7 bits : les ordinateurs utilisaient des cases mémoires de un octet, mais ils réservaient toujours le 8ème bit pour le contrôle de parité (c’est une sécurité pour éviter les erreurs, qui étaient très fréquentes dans les premières mémoires électroniques).
On peut présenter la table des caractères ASCII sous une forme qui met en évidence une organisation fondée sur la base 16.

Dans ce fichier sont énumérés les 128 caractères ASCCI dont les 33 caractères de contrôle (codes 0 à 31 et 127) sont présentés avec leur nom en anglais suivi d'une traduction entre parenthèses. On trouvera quelques détails en plus sur ces caractères de contrôle ici.
Pour coder un texte dans un alphabet plus complexe et pour échanger des informations sur l’Internet, il faut impérativement disposer d’un charset plus complet.
Par exemple, en français les caractères é, è, ç, à, ù, ô, æ, œ, sont fréquemment utilisés alors qu’ils ne figurent pas dans la table ASCII.Il va donc falloir étendre la table ASCII pour pouvoir coder les nouveaux caractères. Les mémoires devenant plus fiables et, de nouvelles méthodes plus sûres que le contrôle de parité ayant été inventées, le 8ième bit a pu être utilisé pour coder plus de caractères.
On élimine ainsi l’inconvénient très gênant de ne coder que les lettres non accentuées, ce qui peut suffire en anglais, mais pas dans les autres langues (comme le français et l’espagnol par exemple). On a pu aussi rajouter des caractères typographiques utiles comme des tirets de diverses tailles et sortes.
Le fait d’utiliser un bit supplémentaire a bien entendu ouvert des possibilités mais malheureusement tous les caractères ne pouvaient être pris en charge. La norme ISO 8859–1 appelée aussi Latin-1 ou Europe occidentale est la première partie d’une norme plus complète appelée ISO 8859 (qui comprend 16 parties) et qui permet de coder tous les caractères des langues européennes. Cette norme ISO 8859–1 permet de coder 191 caractères de l’alphabet latin qui avaient à l’époque été jugés essentiels dans l’écriture, mais omet quelques caractères fort utiles (ainsi, la ligature œ n’y figure pas). Dans les pays occidentaux, cette norme est utilisée par de nombreux systèmes d’exploitation, dont Linux et Windows. Elle a donné lieu à quelques extensions et adaptations, dont Windows-1252 (appelée ANSI) et ISO 8859-15 (qui prend en compte le symbole € créé après la norme ISO 8859-1). C’est source de grande confusion pour les développeurs de programmes informatiques car un même caractère peut être codé différemment suivant la norme utilisée.
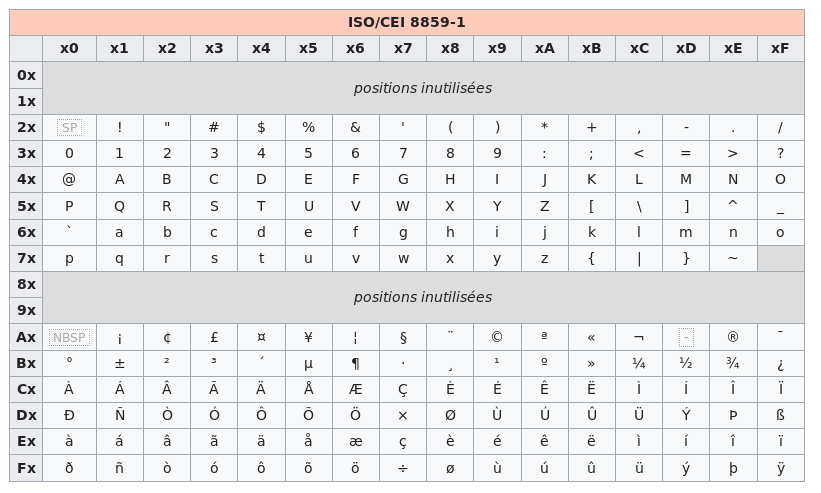
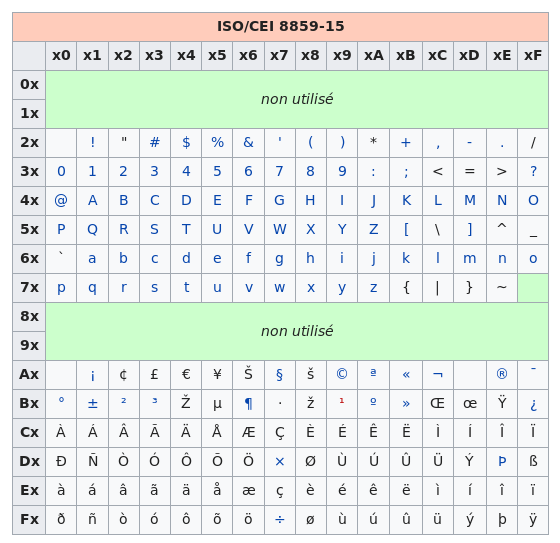
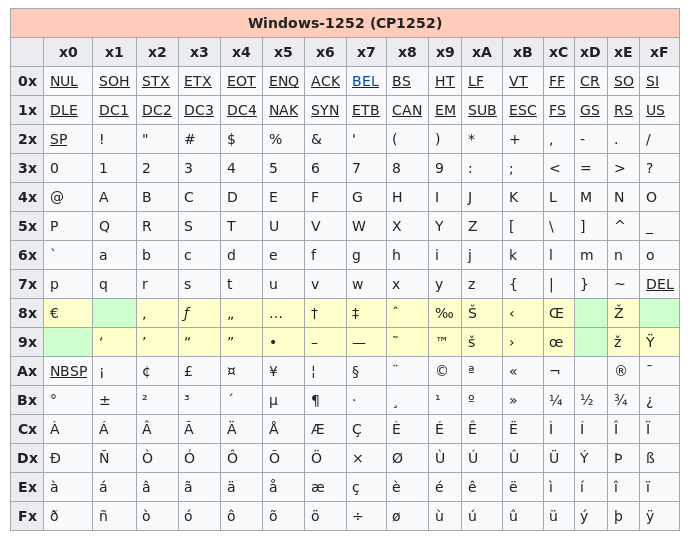

La globalisation des échanges culturels et économiques a mis l’accent sur le fait que les langues européennes coexistent avec de nombreuses autres langues aux alphabets spécifiques voire sans alphabet. La généralisation de l’utilisation d’Internet dans le monde a ainsi nécessité une prise en compte d’un nombre beaucoup plus important de caractères (à titre d’exemple, le mandarin possède plus de 5000 caractères !). Une autre motivation pour cette évolution résidait dans les possibles confusions dues au trop faible nombre de caractères pris en compte ; ainsi, les symboles monétaires des différents pays n’étaient pas tous représentés dans le système ISO 8859-1, de sorte que les ordres de paiement internationaux transmis par courrier électronique risquaient d’être mal compris.
La norme Unicode a donc été créée pour permettre le codage de textes écrits quel que soit le système d’écriture utilisé.
On attribue à chaque caractère un nom, une position normative et un bref descriptif qui seront les mêmes quelle que soit la plate-forme informatique ou le logiciel utilisés. Un consortium composé d’informaticiens, de chercheurs, de linguistes et de personnalités représentant les États ainsi que les entreprises s’occupe donc d’unifier toutes les pratiques en un seul et même système : l’Unicode.
L’Unicode est une table de correspondance Caractère-Code (Charset), et l’UTF-8 est l’encodage correspondant (Encoding) le plus répandu. Il existe d'autres encodings comme UTF-16 ou UTF-32.
Maintenant, par défaut, les navigateurs Internet utilisent le codage UTF-8 et les concepteurs de sites pensent de plus en plus à créer leurs pages web en prenant en compte cette même norme ; c’est pourquoi il y a de moins en moins de problèmes de compatibilité.
Chaque caractère dans Unicode est identifié par un code point unique.
Comme vous avez pu le voir, Unicode inclue tous les langages humains actuels et passés (y compris la dizaine de milliers de caractères chinois), les symboles mathématiques et les emoji.
Ce qu'on a vu doit avoir des répercussions sur notre manière de programmer.
Liser cette page qui explique 5 règles auxquelles faire très attention !
Il vous faudra dorénavant les mettre en application systématiquement (Les 3 premières sont obligatoires).
{kind=link}