Algorithme des k plus proches voisins
( knn = k-nearest neighbors )
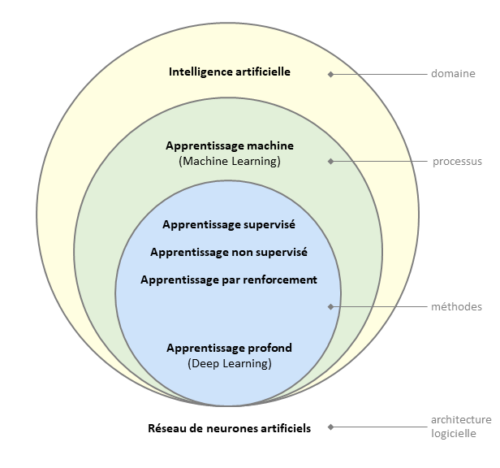
Nous allons voir dans cette partie une classe d'algorithmes permettant de classer des objets (au sens large) dans différentes catégories.
La décision prise par cet algorithme évolue au cours du temps, en fonction des choix qu'il a déjà effectué. C'est pourquoi il est classé comme
un des algorithme les plus simples mettant en œuvre l'intelligence artificielle, et plus précisément, l'apprentissage
automatique supervisé ( un domaine du machine learning ).
L'exemple historique des Iris
En 1936, le biologiste Edgar Anderson cherche à étudier la classification des Iris. Il s'intéresse plus particulièrement à 3 espèces :
- iris setosa
- iris virginica
- iris versocolor



Comme on peut le constater sur les photos ci-dessus, il n'est sûrement pas évident pour un non initié de déterminer l'espèce d'un Iris croisé dans la nature au hasard d'une promenade.
Les données
Edgar Anderson décide donc de mettre au point un test systématique permettant de différencier ces trois espèces.
Pour cela il réalise des mesures sur les pétales et les sépales des Iris; il mesure :
- La largeur et la longueur des sépales
- La largeur et la longueur des pétales

pour un ensemble d'Iris à la même saison, connaissant l'espèce de chaque fleur.
Pour simplifier le traitement des données nous ne prendrons en compte que les mesures des pétales.
Vous trouverez un extrait de ces données ici.
Dans ce fichier les deux premières colonnes correspondent à la largeur et la longueur du pétale, la troisième colonne contient 0, 1 ou 2 en
suivant le code suivant :
- 0 : iris setosa
- 1 : iris virginica
- 2 : iris versocolor
Récupérez le fichier de donnée présenté ci-dessus, et visualisez ces données grâce à ce script :
Ce nuage de point montre qu'il y a une forte corrélation entre longueur et largeur des pétales d'un Iris d'une part, et l'espèce à laquelle il appartient : les mesures des pétales constituent donc un critère de classification des Iris dans une espèce donnée.
Le problème
Ayant les données précédentes à notre disposition, le problème est de déterminer l'espèce d'un Iris inconnu, ne connaissant que la largeur et la longueur de ses pétales.
L'algorithme
Pour résoudre ce problème nous allons utiliser l'algorithme des k plus proches voisins.
Son principe est le suivant :
- Placer l'iris inconnu sur le plan
- Chercher ses k ( k = entier ) plus proches voisins dans ce plan
- Chercher l'espèce majoritaire parmi ces k voisins
- Ajouter l'iris inconnu à l'espèce déterminée
"plus proches" est à prendre au sens littéral de distance la plus petite dans le plan, entre le point représentant l'iris à classer et les iris du jeu de données.
Cet algorithme met en œuvre l'apprentissage automatique ou "machine learning". En effet Chaque nouvel élément va être associé à une espèce
et donc enrichir les connaissances de l'ordinateur, qui pourra ainsi affiner ses choix par la suite.
On commence à voir apparaître une forme d'intelligence artificielle
Pour bien comprendre, illustrons l'algorithme que l'on vient de décrire.
Voici trois iris inconnus ajoutés dans le plan sous la forme d'un point noir :
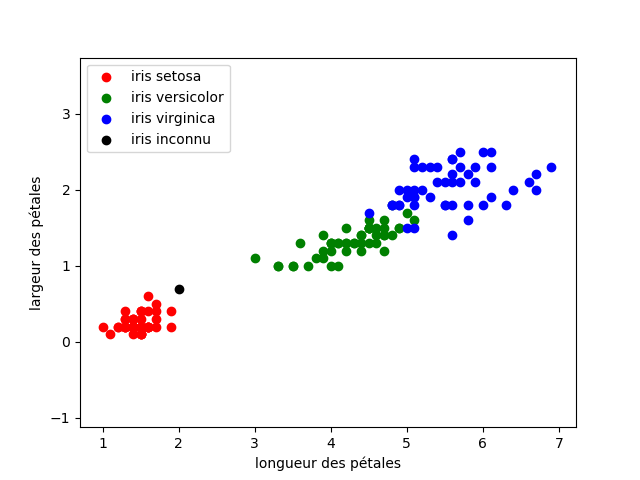
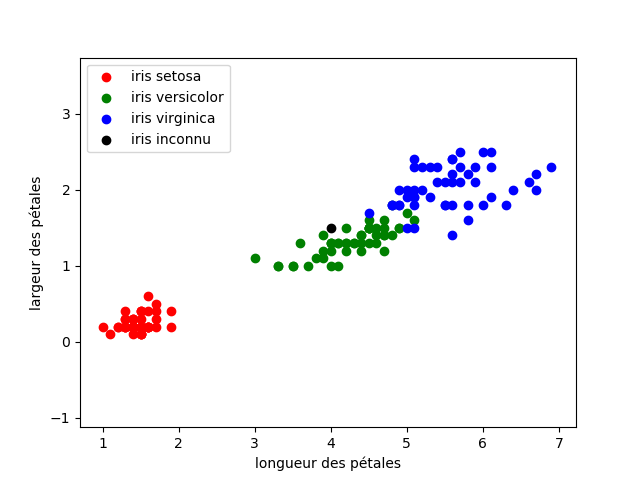
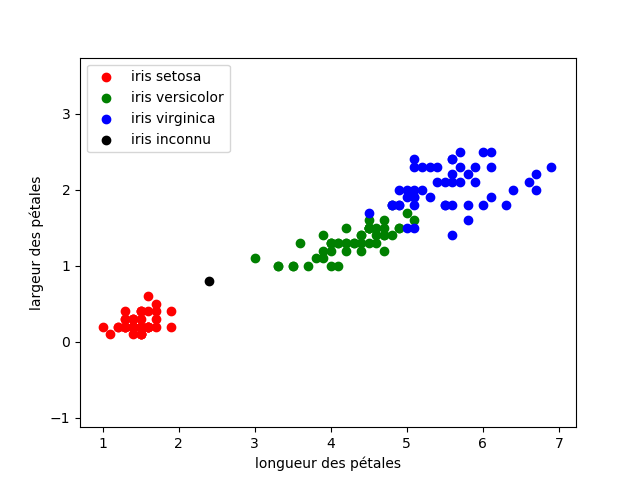
Pour les inconnus 1 et 2, nous pouvons déterminer "à l’œil" l'espèce de l'iris. Pour l'inconnu 3 cela va être plus compliqué, il va falloir calculer les distances aux iris voisins pour choisir l'espèce de l'inconnu 3.
Mise en œuvre de l'algorithme
Structures de données utilisées
Deux structures de données seront mises en œuvre dans le code :
- Les données extraites du fichier csv sont stockées dans un tableau de tableaux du type
[longueur, largeur, espèce]:
que l'on appellera par la suite "tableau de données".[[1.4, 0.2, 0], [1.3, 0.2, 0], ... ] - Lors du calcul des distances entre l'iris inconnu et ses voisins, un nouveau tableau de tableaux sera créé, qui contiendra, pour chaque
iris du tableau de données, un tuple
(distance avec l'iris inconnu, espèce):
que l'on appellera par la suite "tableau des distances et espèces".[(1.4836666666, 0), (1.658975975975, 0), ... ]
Structure du code
Le code sera structuré en fonctions indépendantes :
recup_donnees(nomDeFichier)
permet de stocker les données d'un fichier csv dans une structure du type "tableau de données"affichage_iris(tab)
permet l'affichage dans un plan à partir d'une structure de données du type "tableau de données" (voir ci-dessus).distance(x1, y1, x2, y2)
calcule la distance entre un iris de coordonnées (x1, y1) et un autre iris de coordonnées (x2, y2)tableau_distances(tab, long, larg)
crée le "tableau des distances"k_mini(tab, k)
recherche dans une structure de données du type "tableau des distances", les k éléments les plus proches de l'iris à classer.kppv_iris(iris, long, larg, k):
C'est bien sur ici que tout se passe...La fonction recherche les k plus proches voisins, recherche l'espèce majoritaire puis ajoute au tableau de données le nouvel iris avec son espèce, et renvoie ce tableau.
Travail à réaliser
Fonctions déjà écrites
Les deux fonctions recup_donnees et affichage_iris sont déjà données ci-dessous; appelez successivement les deux fonctions,
pour mettre en mémoire le tableau iris, et pour afficher le nuage de points.
Distance entre deux iris
Écrire une fonction distance, qui prend comme paramètres les coordonnées x et y d'un point 1 du plan et celle d'un point 2,
et qui renvoie leur distance dans le plan ( au besoin, demandez à un de vos camarades de maths la formule pour faire ce calcul 🙄...)
Tableau des distances et espèces
Écrire une fonction tableau_distances, qui prend comme paramètres le tableau de données et les mesures des pétales de l'iris à classer,
et qui renvoie le tableau des distances.
Recherche des k plus proches voisins
Écrire le code d'une fonction k_mini, qui prend comme paramètres le tableau des distances et un entier k, et qui renvoie le tableau
des k éléments du tableau les plus proches de l'iris à classer.
Pour cela, on triera le tableau des distances dans l'ordre croissant, et on sélectionnera les k premiers éléments de ce tableau.
La fonction principale
Compléter la fonction kppv_iris ci-dessous qui implémente l'algorithme des k plus proches voisins.
Tester ensuite le code avec un iris à classer de longueur et de largeur quelconques ( mais de valeurs réalistes...)
Pour la valeur de k, commencer avec 3, puis 5, puis expérimentez !
