Algorithmes utilisant un parcours séquentiel de tableau
Parcourir séquentiellement un tableau, c'est parcourir (tous) ses éléments l'un après l'autre.
Recherche d'une valeur dans un tableau
Nous allons nous intéresser à un algorithme simple : celui de la recherche d'un élément de valeur donnée dans un tableau.
Un tableau au sens algorithmique est implémenté en Python avec un type construit appelé liste Python, que vous avez déjà étudié en détails ici.
En particulier, vous connaissez donc la syntaxe du test d'appartenance d'une valeur à un tableau :
if valeur in tableau:
.................
Mais on ne sait pas ce que Python fait derrière cette syntaxe pour trouver l'élément dans le tableau.
Algorithme "naïf"
L'algorithme
La méthode "naïve", c'est à dire qui est la plus simple, pour trouver un élément dans un tableau est donc la suivante :
→ on parcourt donc le tableau élément après élément; si on trouve la valeur, on sort du parcours et de la fonction en renvoyant VRAI; si on arrive à la fin du parcours et que l'on n'a pas trouvé la valeur, on sort de la fonction en renvoyant FAUX.
Cette façon de procéder est appelée algorithme de recherche séquentielle.
fonction recherche séquentielle:
tant que l'on n'est pas arrivé à la fin du tableau et que l'on n'a pas trouvé la valeur:
si l'élément courant est la valeur recherchée:
on a trouvé la valeur !
sinon:
passer à l'élément suivant
renvoyer VRAI (si on a trouvé la valeur) ou FAUX (si ce n'est pas le cas)
Implémentation
Traduisez l'algorithme en codant une fonction
recherche_seq.Cette fonction prendra en argument un tableau et une valeur à chercher, et renverra un booléen
TrueouFalseselon que la valeur est présente ou non dans le tableau.
A vous de réfléchir à la manière de "se souvenir" au cours de la recherche si on a trouvé ou pas la valeur...
Vous testerez votre recherche sur un tableau de 50 valeurs entières entre 1 et 100 générées aléatoirement.
from random import randint def recherche_seq(tab, valeur): passModifier la fonction de façon à ce qu'elle renvoie :
- le (ou les) indice(s) dans le tableau( sous forme de tableau ) de l' (ou des) élément(s) contenant la valeur recherchée dans le cas où celle-ci s'y trouve
- le tableau vide dans le cas contraire.
Réaliser les mêmes tests que ci-dessus.
from random import randint def recherche_seq_occurrences(tab, valeur): pass
Comparaison avec l'algorithme utilisé par Python
Est-ce l'algorithme utilisé par Python "en interne" pour tester l'appartenance d'une valeur dans un tableau ? Impossible de le savoir directement...mais nous allons essayer de comparer son temps d'exécution avec celui de notre algorithme "naïf".
Pour cela, nous allons utiliser le module timeit qui permet de comparer le temps d'exécution ( ou de plusieurs exécutions ) d'un script Python :
t = timeit(stmt = "code_à_éxécuter", globals=globals(), number = nombre_de_répétitions)
- stmt est une chaîne de caractères donnant le bout de code à exécuter
- number est le nombre de répétitions de l'exécution du code
- Le module mesure la durée moyenne ( en secondes ) de l’exécution des fonctions sur plusieurs exécutions successives ( en effet, cette durée est influencée par de nombreux paramètres
extérieurs au code lui-même et varie donc d'une exécution à l'autre.).
t1contiendra la durée moyenne d'exécution de la recherche séquentielle, ett2celle de la recherche "Python".
- Écrire ci-dessous le code d'une fonction
recherche_python, qui utilise l'opérateurinpour déterminer si une valeur donnée se trouve dans un tableau. - écrire une instruction permettant de générer un tableau de 100 valeurs aléatoires.
- Lancer le script plusieurs fois de suite, et comparer les valeurs de durée obtenues à chaque fois.
Si la fonction
recherche_seqa été précédemment exécutée, elle est en mémoire de la page web : son code est donc "connu" de l'éditeur ci-dessous, et il n'est donc pas nécessaire d'y recopier ce code.from random import randint from timeit import timeit def recherche_python(tab, valeur): pass tab = ... # à compléter ## Code pour comparer le temps d'éxécution des deux fonctions : t1 = timeit(stmt = 'recherche_seq(tab, 15)', globals=globals(), number = 1000) print(t1) t2 = timeit(stmt = 'recherche_python(tab, 15)', globals=globals(), number = 1000) print(t2)Que peut-on conclure ?
Conclusion : complexité temporelle des algorithmes
Coût en temps d'un algorithme
A conditions d'exécution identiques ( même ordinateur, même taille de données à traiter,...) tous les algorithmes ne se valent donc pas : certains sont plus efficaces que d'autre, c'est à dire qu'ils résoudront plus rapidement le problème pour lequel ils sont prévus.
On dit que leur coût en temps (ou coût temporel) est différent : un algorithme efficace aura un coût en temps plus faible qu'un autre algorithme moins efficace.
Dans le cas de notre fonction de recherche séquentielle, l'algorithme a un coût en temps plus grand que celui utilisé en interne par Python, il est donc moins efficace que ce dernier.
( Remarque : on peut aussi comparer les algorithmes en fonction de leur coût en espace, c'est à dire la plus ou moins grande quantité de mémoire dont ils ont besoin pour fonctionner; cependant nous ne nous y intéresserons pas dans ce chapitre et les suivants.)
Contrairement à ce que son nom peut laisser penser, le coût temporel d'un algorithme ne s'exprime pas en unités de temps ( minutes, secondes,...), mais en nombre d'opérations élémentaires à effectuer pour résoudre le problème posé; une opération élémentaire est une opération "de base", "instantanée" du point de vue de l'ordinateur : c'est par exemple une affectation, une comparaison, etc...
Le coût temporel global d'un algorithme va alors dépendre de la nature des opérations élémentaires à effectuer, mais surtout du nombre n de données à traiter.
Dans notre cas, le nombre d'opérations élémentaires à faire est le nombre de comparaisons à réaliser pour déterminer si un élément du tableau est égal à la valeur recherchée.
Nous ne pouvons pas prévoir quand cet algorithme s’arrête, mais nous pouvons dire que:
- Au mieux, on va trouver l'élément dans la première case : on aura donc fait 1 seule comparaison
- Au pire, on parcourra l'ensemble des n éléments du tableau (si l'élément recherché est absent du tableau ou si il est en dernière case) : on aura donc fait n comparaisons.
- En moyenne, si l'élément est présent, on parcourra la moitié du tableau; on aura donc fait n/2 comparaisons.
Généralement, on s’intéresse au coût au temps d'un algorithme dans le pire des cas; ici, on dira donc que le coût en temps de l'algorithme de recherche séquentielle est de n opérations élémentaires pour n données à traiter.
Complexité temporelle d'un algorithme
La complexité temporelle d'un algorithme correspond à l'évaluation du coût en temps d'un algorithme quand la quantité de données qu'il traite augmente.
Elle dépend souvent de la quantité de données notée n.
Généralement, on s'intéresse là aussi à la complexité temporelle dans le pire des cas.
Dans notre cas, le coût en temps de la recherche dans un tableau augmentera proportionnellement avec la taille du tableau : si le tableau contient 30 000 noms, le pire cas demandera
30 000 étapes; avec 60 000 noms, il y aura 60 000 étapes, etc....: le coût en temps est donc proportionnel au nombre n de données à traiter.
On dira que la complexité d'une recherche séquentielle dans un tableau est "en O(n)", ce que l'on appelle une complexité linéaire.
La notation "O(n)" ( "grand O de n" ou "O de n") est une notation mathématique qui résume la définition précédente et nous évite de dire à chaque fois : "dans le pire des cas", "proportionnel à", ...
Attention, l'étude de la complexité d'un algorithme prend du sens quand n devient très grand; pour n = 10 ou n = 20, cette notion n'a en effet pas beaucoup d'intérêt la plupart du temps car on voit alors peu de différence entre les différents algorithmes !
Quelques exemples de complexité
- Si cette recherche ne dépendait pas de la taille n du tableau, on dirait qu'elle est en O(1) ( "en temps constant" )
- Si cette recherche était proportionnelle à n⨯n, on dirait qu'elle est en O(n2) ( "quadratique" )
- Si un algorithme demande par exemple 2⨯n opérations ou 12⨯n opérations, sa complexité sera tout de même en O(n)
- Si dans un algorithme apparaissent plusieurs étapes de complexités différentes, c'est la plus grande d'entre elles qui donne la complexité globale de l'algorithme.
Lien avec la durée d'exécution d'un programme
Mais nous ne parlons ici que de la complexité temporelle d'un ALGORITHME !
Si nous voulons savoir quelle sera la durée d'exécution du programme c'est une autre question :
La complexité temporelle d'un algorithme nous donne des indications sur le coût en temps d'un algorithme, MAIS si la complexité est théorique et ne dépend que de l'algorithme, le temps d'exécution lui est une notion pratique et dépend :
- de la machine sur laquelle on va exécuter le programme
- des autres programmes qui s'exécutent sur la machine
- du système d'exploitation de la machine
- des choix que le programmeur a fait pour coder son algorithme
- et bien d'autres choses encore...
En conclusion la complexité temporelle N'EST PAS le temps d'exécution d'un programme, elle ne permet de comparer que l'efficacité d'ALGORITHMES entre eux.
Vous trouverez sur cette page un peu plus de détails sur cette notion de complexité des algorithmes.
Extremum ( maximum ou minimum ), moyenne
L'algorithme de recherche d'une valeur dans un tableau est basé sur le parcours du tableau et la comparaison de chaque élément à la valeur recherchée.
Sur cette base nous pouvons imaginer des traitement différents des éléments du tableau.
Tous les algorithmes suivants étant basé sur le parcours intégral d'un tableau, leur complexité temporelle est donc O(n) dans tous les cas.
Recherche du maximum
L'algorithme de recherche d'un maximum est le suivant :
fonction maximum:
maxi ← premier élément du tableau
pour chaque élément successif du tableau:
si valeur de l'élément > maxi
maxi ← valeur de l'élément
fin si
fin pour
renvoyer maximum
Vous devez coder la fonction maximum_tableau qui renvoie la valeur maximale dans un tableau.
Vous n'oublierez pas les annotations et la docstring
Tester le bon fonctionnement de votre fonction à l'aide du jeu de tests proposé.
Recherche du minimum
- écrire l'algorithme permettant de déterminer le minimum dans un tableau
- écrire une fonction
minimum_tableaurenvoyant le minimum d'un tableau - compléter la fonction avec les tests unitaires sur les tableaux du 2.1.
Calcul d'une moyenne
L'algorithme de calcul d'une moyenne est le suivant :
fonction moyenne:
somme ← 0
pour chaque élément successif du tableau:
somme ← somme + élément
fin pour
moyenne ← somme / n ( n = nombre d'éléments du tableau )
renvoyer moyenne
- écrire une fonction
moyenne_tableaurenvoyant la moyenne des éléments d'un tableau.
Vous n'oublierez pas les annotations ( attention au type du résultat renvoyé ! ) et la docstring - compléter la fonction avec quelques tests unitaires bien choisis
- utiliser ensuite la fonction avec les tableaux du 2.1.
Applications
Les algorithmes à utiliser dans les applications suivantes ne sont pas tous en O(n).
Si on vous demande de le faire, essayez alors de déterminer la complexité en temps de l'algorithme utilisé.
Le mot le plus long
Compléter la fonction mot_le_plus_long ci-dessous qui prend en paramètre un tableau non vide tab de mots et renvoie un tuple constitué :
- du mot le plus long,
- et de la longueur de ce mot le plus long.
En cas d'égalité entre plusieurs mots ayant la longueur maximale, on renverra celui ayant le plus petit indice.
Tester votre fonction en utilisant le jeu de tests ci-dessous :
mot_le_plus_long(['chaton', 'licorne', 'ratatouille', 'bip']) == ('ratatouille', 11)
mot_le_plus_long(['chatons', 'licorne', 'or', 'car', 'etoile']) == ('chatons', 7) # l'ordre des mots
mot_le_plus_long(['licorne', 'chatons', 'or', 'car', 'etoile']) == ('licorne', 7) # influe sur le résultat
Recherche des deux premiers maximums
Et si ce n'était pas l'unique valeur la plus grande, mais les deux plus grandes, que l'on cherchait dans un tableau ?
L'algorithme de recherche du maximum n'est pas difficile à adapter pour cela : au lieu de ne stocker qu'une seule valeur maximale, on va en stocker deux, que l'on affectera selon l'algorithme suivant :
- on initialise deux variables max1 et max2.
- pour chaque élément du tableau,
- Si valeur de l'élément > max1, alors on met à jour max2 puis max1,
- Sinon, si valeur de l'élément > max2, alors on met à jour max2 uniquement.
A vous de réfléchir à comment "mettre à jour" (= actualiser la valeur de ) max1 et/ou max2 😎...
Écrire une fonction deux_max, qui prend en paramètre un tableau d'entiers, et qui renvoie le tuple des deux plus grandes valeurs dans le tableau.
Tester la fonction avec l'exemple donné, puis avec un tableau contenant un ensemble de valeur aléatoires.
Face au Soleil...
On dispose d'un tableau contenant des valeurs entières correspondant à la hauteur de buildings placés les uns à côté des autres.
Le Soleil est situé à gauche des buildings, soit "du côté du début du tableau" :
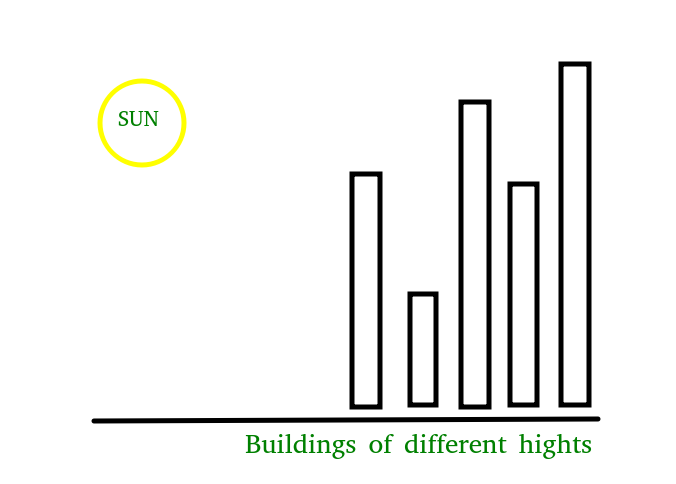
Les hauteurs des buildings ci-dessus seraient codées par le tableau : buildings = [4, 2, 5, 4, 6]
Le but est de compter le nombre de buildings au sommet desquels on verra effectivement le Soleil couchant; pour cela, la hauteur d'un building doit être strictement supérieure à celle des buildings situés à sa gauche : ainsi ci-dessus, seuls le premier, le troisième et le dernier building verront le Soleil couchant, soient les éléments du tableau aux indices 0, 2 et 4.
- écrire une fonction
building_sunset, qui :- prend comme paramètres un tableau d'entier modélisant les hauteurs des buildings
- renvoie le nombre de buildings au sommet desquels on voit le Soleil couchant
- écrire une deuxième version de la fonction, qui renvoie cette fois les indices des buildings dans le tableau de hauteurs.
- tester les fonctions avec un tableau de valeurs entière aléatoires.
- Indiquer, en la justifiant, la complexité en temps de l'algorithme utilisé.
Profit maximum
Le cours ( ou cotation ) d'une action en bourse, c'est à dire sa valeur, fluctue au cours du temps : quand beaucoup de gens achètent cette action, sa valeur augmente, et inversement, sa valeur diminue quand beaucoup de gens la vendent.
Le cours d'une action peut être représenté par un tableau de valeurs, chaque élément de ce tableau indiquant par exemple le prix de cette action jour après jour :
[100, 101, 102, 101, 98, 98, 95, 91, 93, 88, 90, 89, 92, 95, 99, 95, 97, 98, 103, 102, 104, 105, 108, 104, 102, 98, 93, 94, 94, 89, 93]
Le profit est égal à la différence entre le prix de revente et le prix d'achat de l'action; le but est (bien entendu 😒) d'acheter et de revendre aux bonnes dates afin de réaliser le profit maximal !...
Méthode "naïve"...
La première idée qui vient à l'esprit est d'essayer toutes les possibilités : pour chaque date d'achat i, calculer le profit pour une revente à chaque date j ultérieure à i, et chercher la valeur maximale parmi tous ces profits possibles.
Cette méthode où l'on teste toutes les possibilités afin de trouver la valeur optimale s'appelle méthode par force brute, car
on ne "réfléchit" pas à utiliser un moyen efficace, on essaye systématiquement tout ce que l'on peut essayer...ce n'est souvent pas la meilleure façon
de faire, car le nombre de possibilités peut dans certains cas devenir trèèèèèès grand...
Mais c'est envisageable dans notre cas, car le tableau n'est pas très grand, donc les possibilités ne sont pas en (très) grand nombre.
Pour déterminer les dates d'achat et de vente, on va alors utiliser le principe suivant :
pour chaque date i dans le tableau de valeurs :
pour chaque date j dans le tableau, avec j > i :
calculer le profit si on achète à la date i et on revend à la date j
déterminer si ce profit est le profit maximum
La date de revente doit bien entendu être postérieure à la date d'achat, on ne peut pas revendre une chose que l'on ne possède pas encore...
- Écrire une fonction
profit_maximum, qui :- prend en paramètre un tableau de valeurs de cotation d'une action,
- renvoie la valeur du profit maximum
- Tester votre fonction avec les tableaux proposés.
- compléter (éventuellement) votre fonction pour qu'elle renvoie en plus la date d'achat et la date de revente pour réaliser ce profit maximum.
Les deux dates seront renvoyées comme indices dans le tableau de valeurs. - Indiquer, en la justifiant brièvement, la complexité en temps de l'algorithme utilisé ici.
Deuxième version
Il existe une autre façon de faire pour résoudre ce problème, beaucoup plus réfléchie :
pour chaque date i dans le tableau de valeurs:
si le prix à la date i est plus petit que le meilleur prix d'achat courant:
alors on a trouvé une meilleure date d'achat
sinon :
on calcule le profit en revendant à la date i
si ce profit est plus grand que le meilleur profit courant:
alors on a trouvé un meilleur profit !
En gros, cet algorithme traduit vraiment que l'on doit acheter quand le prix est au plus bas, et revendre quand il est au plus haut !!
- Écrire une fonction
profit_maximum_v2, qui :- prend en paramètre un tableau de valeurs de cotation d'une action,
- renvoie la valeur du profit maximum, ainsi que la date d'achat et la date de revente pour réaliser ce profit maximum.
Les deux dates seront renvoyées comme indices dans le tableau de valeurs.
- Tester votre fonction avec les tableaux proposés.
- Indiquer, en la justifiant brièvement, la complexité en temps de l'algorithme utilisé ici. Que remarque-t-on ?
Plus longue période de gel
Un météorologue a relevé les températures au lever du jour dans sa rue. Il souhaite déterminer la durée de la plus longue période de gelées consécutives durant ces relevés, c'est à dire le plus grand nombre de jours successifs où la température est restée inférieure ou égale à 0°C.
Les températures sont données sous forme d'un tableau de nombres :
temperatures = [2, -3, -2, -5, -4, 0, 1, 2, -1, -2]
Dans ce tableau, la plus longue période de gel est de 5 jours.
Écrire une fonction longueur_gel qui prend en paramètre un tableau de températures, et qui renvoie la longueur de la plus longue séquence de nombres négatifs ou nuls consécutifs
dans le tableau.
Vous pouvez essayer une méthode analogue à la "force brute" évoquée précédemment ( tester toutes les possibilités ), mais il existe une façon beaucoup plus judicieuse de procéder; pourrez-vous la trouver ?
Faire les tests proposés ( attention notamment à ce que votre code "passe" le dernier test...).
Éventuellement, vous pourrez faire en sorte que votre fonction renvoie, en plus, les dates délimitant la plus longue période de gel.
Suivi par un GPS de sport
Introduction
On peut ainsi retrouver son parcours sur une carte, la durée écoulée pour chaque kilomètre, la vitesse instantanée, le kilomètre le plus rapide lors de l'activité etc...

Données disponibles
Les donnés brutes extraites d'une montre GPS se présentent sous cette forme pour chaque point enregistré :
<Trackpoint>
<Time>2021-10-17T09:58:15Z</Time>
<Position>
<LatitudeDegrees>45.5668804</LatitudeDegrees>
<LongitudeDegrees>5.9177179</LongitudeDegrees>
</Position>
<AltitudeMeters>273.1518555</AltitudeMeters>
<DistanceMeters>0.1047208</DistanceMeters>
<SensorState>Absent</SensorState>
</Trackpoint>
Nous allons simplifier cela et vous travaillerez à partir d'un tableau python contenant la durée de chaque tranche de 100 m effectuée :
[49.49, 32.37, 33.02, 33.55, 42.14, 34.6, 42.38, 32.34, 41.6, 37.03, 41.22, 37.9]
Recherche du meilleur 100 m
Vous devez dans cette partie coder une fonction qui renvoie le temps du meilleur 100 m.
Cette fonction prendra en argument un tableau contenant les durées de toutes les tranches de 100 m.
Pour simplifier votre travail vous trouverez ci-dessous un code qui génère un tableau à traiter pour un parcours de 10 km.
Recherche du meilleur kilomètre
Rechercher le meilleur 100 m c'est facile, mais sur une course de 10 km cela a peu d'intérêt.
Nous allons donc tenter de rechercher le meilleur km dans le tableau précédent.

Mais sur une course de 10 km il n'y a pas que 10 fois 1 km à vérifier...comme vous pouvez le constater sur le schéma ci-dessous :
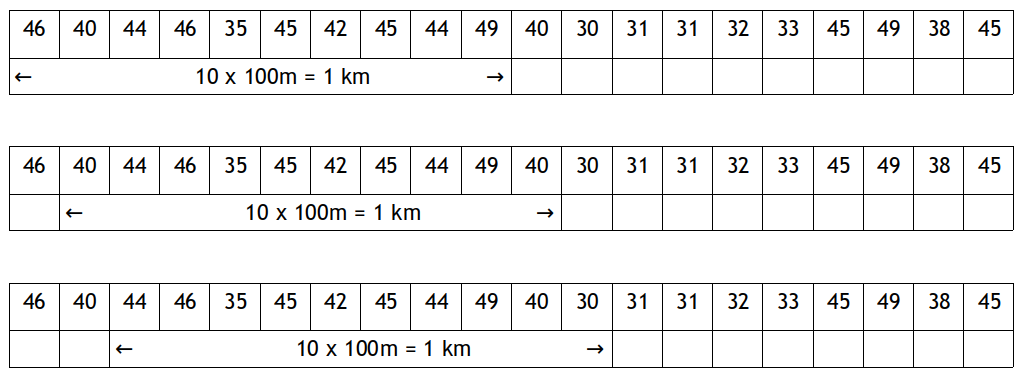
Vous devez dans cette partie coder une fonction qui renvoie le temps du meilleur km.
Cette fonction prendra en argument un tableau contenant les durées de toutes les tranches de 100 m.
Dit ainsi, c'est la méthode "force brute" que l'on est obligé d'utiliser ici; et pourtant, il existe une méthode plus judicieuse ( mais aussi plus délicate à coder...).
Preuve d'algorithme : Terminaison et Correction
Nous allons dans cette partie commencer à nous poser une question que nous reverrons en algorithmique cette année : la question de la preuve d'un algorithme.
Pourquoi une preuve ?
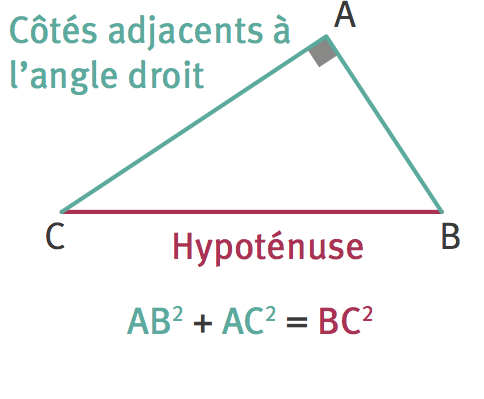
Vous connaissez le théorème ci-contre et vous savez très bien dessiner un triangle rectangle quelconque et vérifier que ce théorème est correct.
Mais vous savez aussi que ce théorème a été démontré et qu'au delà de tous les tests que l'on pourrait faire, il a été vérifié théoriquement.
Et bien c'est la même chose pour les algorithmes; on peut :
- Les utiliser (en supposant qu'ils fonctionnent bien)
- Les tester avec des batteries de valeurs particulières ( les tests unitaires que vous avez faits ci-dessus )
Mais il est aussi nécessaire de les démontrer.
Comment structurer le raisonnement ?
Nous n'allons pas aujourd’hui démontrer un algorithme mais uniquement voir les deux choses qu'il faudrait démontrer...
Terminaison
La première chose à démontrer c'est sa terminaison, c'est à dire le fait qu'il va s'arrêter, en dehors de toute autre considération.
En effet un algorithme, la plupart du temps, effectue un grand nombre d'actions et utilise donc une boucle. Il est important de savoir si l'algorithme va s'arrêter ( sans chercher à savoir s'il remplit bien son rôle ).
Par exemple dans l'algorithme de recherche de maximum que nous venons de voir :
mettre 0 dans maximum
pour tous les éléments du tableau
si élément > maximum
mettre élément dans maximum
renvoyer maximum
On peut constater que :
- l'algorithme parcourt tous les éléments du tableau sans les modifier.
- Le test de comparaison est effectué pour chaque élément du tableau
- Une fois tous les éléments parcourus, l'algorithme s'arrête
Comme le tableau a nécessairement une longueur finie ( contrairement aux mathématiques, rien ne peut être infini en informatique, sauf certaines boucles mal codées...) l'algorithme va nécessairement se terminer.
Nous venons de prouver la terminaison de l'algorithme ( sans, encore une fois, avoir prouvé que celui ci nous donnait bien le maximum du tableau ).
Correction et invariant de boucle
La deuxième chose à démontrer pour un algorithme c'est sa correction, le fait qu'il est correct, qu'il remplit bien le rôle pour lequel il a été conçu.Par exemple :
- Qu'un algorithme de recherche trouve bien l'élément cherché
- Qu'un algorithme de tri rend bien un tableau trié...
Et cette démonstration va s'appuyer sur une notion importante : l'invariant de boucle.
En effet un algorithme, la plupart du temps, effectue un grand nombre d'actions et utilise donc une boucle.
Pour appuyer la démonstration il faut donc trouver une proposition vraie tout au long du déroulement de l'algorithme.
Par exemple dans l'algorithme de recherche que nous venons de voir :
pour tout les éléments du tableau
si l'élément est l'élément recherché
renvoyer Vrai
renvoyer Faux
Un invariant de boucle pourrait être :
"l'élément cherché est placé entre l'élément courant et la fin du tableau"
Ces notions de démonstration et d'invariant de boucle ne sont pas faciles a aborder, car, la plupart du temps, la compréhension de l'algorithme semble nous rendre inutile sa démonstration... Mais sur des algorithmes plus complexes c'est une démarche mathématique importante.
Conclusion
Quand on a démontré que :
- L'algorithme se termine ( preuve de terminaison )
- L'algorithme est correct ( preuve de correction )
On a alors réalisé une preuve mathématique de l'algorithme. On est sur de son bon fonctionnement dans n'importe quelle situation.
Il reste alors à le coder et un "bon" algorithme peut être "mal" codé, il faut donc bien faire attention, dans la phase d'implémentation, à respecter l'algorithme tel qu'il a été écrit.
QCM
Voici quelques questions pour tester si vous avez bien compris les notions de complexité et de preuve d'un algorithme.