Représentation d'un texte en machine
Comme vous l'avez vu, un ordinateur ne stocke et ne lit que des "0" et des "1".
Nous avons vu comment coder des entiers positif, négatifs et des réels avec le système de la virgule flottante.
Nous verrons ici quelles solutions ont été choisies pour coder des caractères.
Charset et Encoding
En télécommunications et en informatique, un jeu de caractères codés (charset encoding en anglais) est un code qui associe un jeu de caractères d’un alphabet avec une représentation numérique pour chaque caractère de ce jeu. Le jeu de caractère est nommé charset (character set) et le code qui relie chaque caractère à un nombre est nommé encoding.

Code morse
Par exemple, le code Morse (qui associe l’alphabet latin à une série de pressions longues et de pressions courtes sur le manipulateur morse du télégraphe) est un des premier jeux de caractères codés.
Le code ASCII et qui signifie American Standard Code for Information Interchange) s’est imposé au début de l’ère informatique pour coder 128 lettres, chiffres et autres symboles.
Le code ASCII
Le code ASCII (on prononce [askiː] ; American Standard Code for Information Interchange) permet de coder les caractères les plus utilisés en langue anglaise : les lettres de l’alphabet en majuscule et en minuscule sans les accents, les dix chiffres arabes, des signes de ponctuation quelques symboles et certains caractères spéciaux invisibles (espace, retour-chariot, tabulation, retour-arrière, etc.).
Ce code est limité à 128 caractères, pour qu’ils puissent être codés avec seulement 7 bits : les ordinateurs utilisaient des cases mémoires de un octet 8 bits), mais ils réservaient toujours le 8ème bit pour le contrôle de parité (c’est une sécurité pour éviter les erreurs, qui étaient très fréquentes dans les premières mémoires électroniques, le premier bit était mis à "0" si la somme des 7 autres était paire et à "1" sinon).
On peut présenter la table des caractères ASCII sous une forme qui met en évidence une organisation fondée sur la base 16.
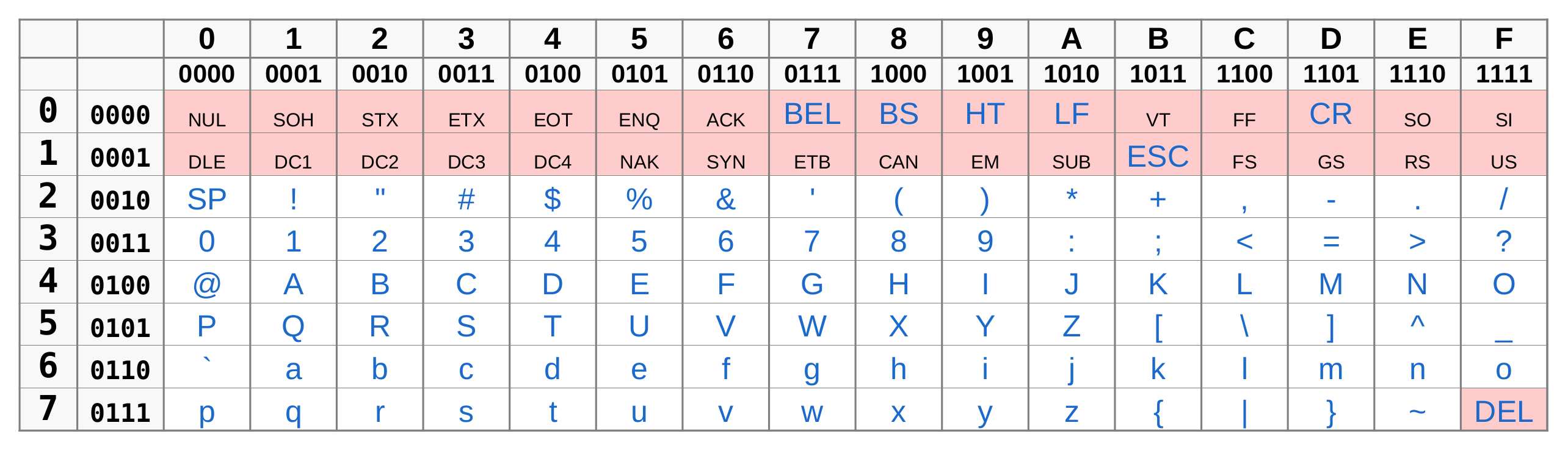
table ASCII
Dans ce fichier sont énumérés les 128 caractères ASCCI dont les 33 caractères de contrôle (codes 0 à 31 et 127) sont présentés avec leur nom en anglais suivi d'une traduction entre parenthèses.
- Avec un encodage ASCII, sur combien de bits est encodé un caractère ?
- Vérifier que le code ASCII de l'espace (noté SP) est 0010 0000.
- Quel est le code ASCCI de la lettre a ? de la lettre A ?
- A l'aide de la table ASCII, coder en binaire la phrase : VIVE LA NSI
- Que signifie cette phrase codée en binaire :
01000010 01110010 01100001 01110110 01101111 00100001. - Quelle est la taille (en octets) de la phrase : Enfin ! Je viens de comprendre ce qui s’est produit. (attention, il faut compter les espaces, et signes de ponctuation…) ?
- Vérifier en tapant cette phrase avec un éditeur de texte quelconque. Il suffit d’écrire le texte, puis de l’enregistrer en tant que « texte brut » (le plus souvent avec une extension .txt) et ensuite de vérifier la taille en octets du fichier obtenu (ce qui peut se faire en cliquant d’abord avec le bouton droit sur l’icône du fichier puis sur « Propriétés »).
- Écrire la même chose dans un logiciel de traitement de texte (comme LibreOffice Writer). Expliquer pourquoi la taille du fichier n’est pas la même.
- Pourquoi, historiquement, ne trouve-t-on pas de lettre accentuée dans la table ASCII ?
- la table ASCII code 128 caractères
- chaque caractère est codé sur 8 bits (dont un bit de vérification par parité)
- cette table est limitée car elle ne contient pas les accents !
Quand la table ASCII ne suffit pas, le codage ISO - 8859
Pour coder un texte dans un alphabet plus complexe, il faut impérativement disposer d’un charset plus complet.
Il va donc falloir étendre la table ASCII pour pouvoir coder les nouveaux caractères. Les mémoires devenant plus fiables et, de nouvelles méthodes plus sûres que le contrôle de parité ayant été inventées, le 8ième bit a pu être utilisé pour coder plus de caractères.
Le fait d’utiliser un bit supplémentaire a bien entendu ouvert des possibilités :
- Ajouter les caractères manquants
- Ajouter des caractères de ponctuation supplémentaires ...
C'est la première partie d'une norme plus complète appelée ISO 8859 qui comporte 16 parties !
Cette norme a donné lieu à quelques extensions et adaptations, dont Windows-1252 (appelée ANSI) et ISO 8859-15 (qui prend en compte le symbole € créé après la norme ISO 8859-1).
(bref, ce n'est plus une norme...)


tables ISO-8859 (1 et 15)
- Combien de caractères ont été codés avec la table ASCII ? Sur combien de bits ?
- Combien de bits utilisent les 3 tables d'encodage ci-dessus ?
Combien de caractères peut-on encoder au maximum ? - Voici le code binaire d'un texte : 01000010 01110010 01100001 01110110 01101111 00101100 00100000 01110100 01110101 00100000 01100001 01110011 00100000 01110000 01110010 01100101 01110011 01110001 01110101 01100101 00100000 01110100 01101111 01110101 01110100 00100000 01110100 01110010 01101111 01110101 01110110 11101001 00101110 00101110 00101110

Convertir ce texte qui est écrit dans l'un des 3 encodages fournis ci-dessus. - Est-ce que la table ASCII est totalement compatible avec l'ISO8859-15 ?
- Ouvrez ce lien sous
Firefox. Vous pouvez constater que le navigateur ne décode pas correctement tous les caractères. Modifier l'encodage utilisé pour décoder le texte (menu
plus->encodage du texte. Qu'observez-vous ?
- la table ISO 8859 peut coder jusqu'à 256 caractères
- chaque caractère est codé sur 8 bits (pas de bit de vérification par parité)
- De nombreuses normes ISO-8859 existent (de ISO-8859-1 à ISO-8859-15) et cela entraîne des confusions
- le nombre de caractère est encore très limité au regard de la diversité linguistique mondiale
La norme Unicode et UTF-8
Les normes précédentes, sont peu satisfaisantes :
- ASCII est trop limitée et ne peut pas coder tout...
- ISO-8859 a été trop adaptée, la confusion est trop grande, et elle était encore limitée face à la diversité mondiale.
On attribue à chaque caractère :
- un nom
- un bref descriptif
- un codage qui sera le même quelle que soit la plate-forme informatique ou le logiciel utilisés (de code point unique est souvent représenté en décimal et en hexadécimal).
Prenons un exemple avec un caractère "exotique" :
- Caractère: ᳇
- Nom (en anglais): Sundanese Punctuation Bindu Ba Satanga
- Code Point en décimal: 7367
- Code Point en hexadécimal: 1CC7
- Notation standard: U+1CC7
- Code HTML
& # 7367
L’Unicode est une table de correspondance Caractère-Code (Charset), et l’UTF-8 est l’encodage correspondant (Encoding) le plus répandu. Il existe d'autres encodings comme UTF-16 ou UTF-32.
Maintenant, par défaut, les navigateurs Internet utilisent le codage UTF-8 et les concepteurs de sites pensent de plus en plus à créer leurs pages web en prenant en compte cette même norme ; c’est pourquoi il y a de moins en moins de problèmes de compatibilité.
On voit ici la progression de l'utilisation de la norme UTF-8 face aux autres.:
tables ISO-8859
Comme vous pouvez le voir ici (bon courage pour scrooler vers le bas...), Unicode inclut tous les langages humains actuels et passés (y compris la dizaine de milliers de caractères chinois, les runes, les hiéroglyphes !, les symboles mathématiques et même les emojis !)
- Ouvrez ce lien sous Firefox. Comme vous le savez sûrement (et comme on va l'étudier cette année) les pages web que nous visualisons sont codées en langage html. Pour visualiser le code html de la page il suffit d'appuyer sur les touches
Ctrl+u
Quelle expression détermine le jeu de caractère (charset) utilisé ? - Ouvrir sous linux un terminal et taper la commande locale. Elle permet d'afficher les différents encodages utilisés sur la machine. Quels sont-ils ?
- Sous linux, lancer le logiciel gucharmap à partir d'un terminal. Ce logiciel permet de voir tous les caractères codés en UTF-8 par langue.
Dans UTF-8, est-ce seulement des langues vivantes qui ont été encodées ? - L’encodage UTF-8 utilise 1, 2, 3 ou 4 octets pour coder en binaire les caractères. Combien de valeurs peut-on coder sur 4 octets ?
- Récupérer le fichier fables.zip et le décompresser dans un répertoire afin de récupérer tous les fichiers qu'il contient
- Exécutez le programme « fable.py ». A quoi correspondent les caractères
\r\naffichés lors de l'exécution du programme ? - Déterminer leur code ASCII en hexadécimal
- Exécutez le programme « fable_v2.py ». Et répondre en justifiant aux questions suivantes
- Le poids du fichier « fable_ascii.txt » correspond-il à 703 octets ?
- Le poids du fichier « fable_iso88591.txt » est-il égal lui aussi à 703 octets ?
- Donner le code binaire du caractère 🦊 présent dans le fichier « fable_utf8_symboles.txt »

QCM d'entrainement
Pour finir, un QCM d'entrainement pour voir si vous avez bien compris l'essentiel- Identifier l’intérêt, les défauts et les qualités des différents systèmes d’encodage.
- Convertir un fichier texte dans différents systèmes d'encodage