NSI Première

Nous allons étudier une grande "famille" d'algorithmes : Les algorithmes gloutons (ou "greedy algorithm" en anglais).
Mais avant de définir les grandes lignes caractérisant cette classe, nous allons nous intéresser à un exemple classique, de la vie courante,
où vous utilisez un algorithme glouton sans le savoir...
Le rendu de monnaie est un problème du quotidien :
vous devez rendre 4,24€ avec un système de pièces et de billets donnés, en minimisant le nombre de pièce ou billets rendus.
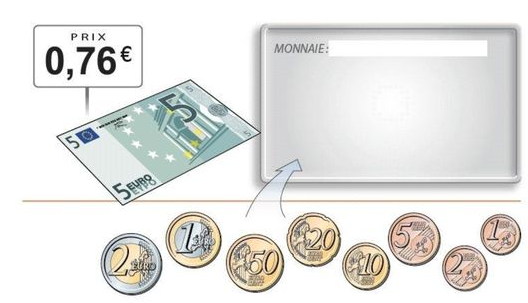
Vous avez déjà résolu ce problème de nombreuses fois, en suivant un algorithme "instinctif".
Nous allons essayer d'analyser votre résolution de ce problème et tenter de généraliser votre démarche à n'importe quelle somme
et à n'importe quel système de monnaie (ensemble de pièces et de billets existants).
Le problème du rendu de monnaie c'est :
monnaie=[pièce1, pièce2, ..., billet1, billet2, ...],Pour bien comprendre la démarche à suivre nous allons commencer par rendre quelques sommes "à la main".
Nous allons considérer notre système de monnaie européen (sans les centimes): monnaie = [1, 2, 5, 10, 20, 50, 100, 200, 500].
Cet exemple est "trivial", nous allons donc nous intéresser à un exemple plus difficile...
Une fois que vous avez traiter ces deux exemples, nous allons nous orienter vers la formalisation de l'algorithme que vous utilisez instinctivement. Pour cela répondez aux questions suivantes :
Si vous avez répondu correctement aux questions précédentes, vous avez réussi à cerner l'algorithme que vous appliquez naturellement pour rendre la monnaie. Vous allez maintenant programmer cet algorithme.
Écrire une fonction rendu_glouton répondant aux spécifications suivantes :
Tester votre fonction sur les appels proposés, que vous avez étudiés ci-dessus ( et dont vous connaissez donc la solution ! )


Si votre fonction fonctionne correctement, vous avez réussi à programmer votre premier algorithme glouton; mais quelles sont les grands principes de cette classe d'algorithmes ?
Un algorithme glouton est un algorithme qui fait, à chaque étape de son exécution, un choix local optimal, sans retour en arrière ni anticipation des étapes suivantes, en "espérant" que cela conduise à une solution globale optimale.
Les algorithmes de cette classe n'étudient donc pas systématiquement toutes les solutions possibles afin d'en déduire la meilleure ( algorithmes dits de "force brute"), mais ils sont beaucoup plus rapides.
Dans l'exemple précédent, nous avions à chaque étape :
Et dans notre cas, CA MARCHE !!!.
Mais...les algorithmes gloutons ne "fonctionnent" pas toujours :
[4,3,1], en suivant votre algorithme. Est-ce optimal ? Justifier.
2. Rendez 8€ avec le système suivant [10,5,2]; mêmes questions ?
Pour information, notre système de monnaie européen a été mis au point pour que l'algorithme de rendu de monnaie glouton soit toujours optimal !
Le problème du sac à dos est un problème d'optimisation classique de l'informatique que nous allons tenter de résoudre grâce aux algorithmes gloutons.
Nous allons imaginer un voleur en train de dévaliser un appartement.
et il a devant lui plusieurs objets :
Il doit donc optimiser le remplissage de son sac.

La technique de "force brute" consiste à attaquer un problème frontalement et à explorer toutes les possibilités en profitant de la force de calcul d'un ordinateur.
C'est une technique qui peut, par exemple, être utilisée pour trouver un mot de passe inconnu, en testant toutes les possibilités.
On peut remarquer qu'avec 4 objets, le problème est déjà assez complexe !
Mais dès que l'on dépasse 40 objets, un ordinateur actuel est incapable de le résoudre raisonnablement de cette façon !
En effet la complexité de ce problème en en O(2n), où n est le nombre d'objets.

Comme on vient de le voir, il n'est pas envisageable de tester tous les cas, surtout si le nombre d'objets dépasse 30 ou 40.
Nous allons donc tenter d'appliquer la technique de l'algorithme glouton à ce problème.
Mais comment faire ?
Faut-il choisir initialement le plus petit objet, ou celui qui rapporte le plus ?
Et bien il faut OPTIMISER.
Nous allons donc calculer pour chaque objet sa "valeur massique" c'est à dire ce que rapportera un kg de cet objet :
Pour résoudre ce problème il faut d'abord penser à la structure de données qui pourra contenir la liste d'objets.
Sachant que chaque objet a 4 caractéristiques :
Il va donc être judicieux d'utiliser pour caractériser chaque objet un dictionnaire {nom, masse, valeur, gain_massique}; l'ensemble de ces dictionnaires sera alors
stocké dans un tableau liste_objets :
liste_objets = [
{"nom": "objet1", "masse": 13, "valeur": 700, "val_mas": None}, # pour l'instant, la valeur massique n'a pas encore été calculée
{"nom": "objet2", "masse": 12, "valeur": 400, "val_mas": None},
{"nom": "objet3", "masse": 8, "valeur": 300, "val_mas": None},
{"nom": "objet4", "masse": 10, "valeur": 300, "val_mas": None}
]
Écrire une fonction calcule_gain, qui prend comme paramètre la liste des objets, et qui renvoie cette liste complétée avec la valeur massique
calculée de chaque objet.
Nous allons ici utiliser la fonction sort de Python, que vous avez déjà utilisée pour trier des tables de données.
cle_tri, qui sera utilisée comme critère de tri pour le tableau liste_objets.sort pour trier la liste des objets par valeur massique décroissante.sac_a_dosVoici ci-dessous un code incomplet, complétez le et testez le sur la liste d'objets données en introduction :
C'est bien gentil, une liste de 4 objets...mais on aimerait savoir si l'algorithme résoudrait aussi, le problème avec une liste de 40 objets par exemple sans y passer la vie entière !
La fonction ci-dessous renvoie une liste aléatoire de n objets; utiliser cette fonction pour tester la robustesse de votre fonction sac_a_dos :
Ne pas donner une valeur trop grande à n...
Mais au fait, est-ce que notre algorithme glouton nous propose toujours "LA" solution optimale ?
Dans le cas de la liste liste_objets que vous avez utilisé pendant cette partie, cela semble être le cas.
On considère deux objets, l'un de 1 kg et l'autre de 30 kg.
Comme on l'a déjà dit, la "force brute" ne permet pas de trouver une solution quand il y a trop d'objets.
L'algorithme glouton lui proposera toujours rapidement une solution; elle ne sera "pas trop mauvaise" mais ne sera pas toujours optimale...
Il existe des solutions algorithmiques optimales à ces problèmes, qui peuvent faire appel, par exemple
à la programmation dynamique vue en classe Terminale.
C'est la fête du cinéma ! Les salles de votre ville ont programmé une série de films qui seront projetés pendant 8h d'affilée.
Une quinzaine de films sont à l'affiche, qui n'ont pas la même heure de projection, ni la même durée; voila le planning prévu de projection :
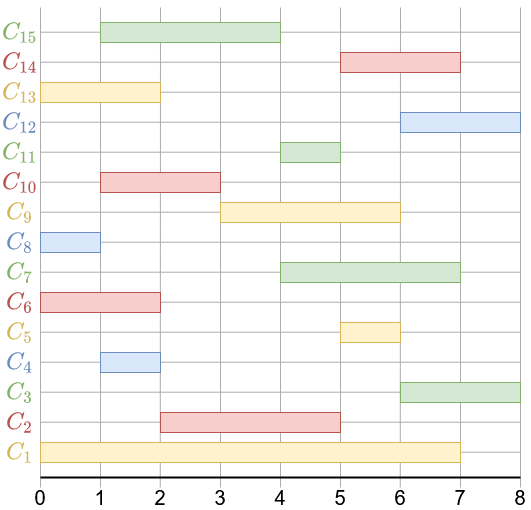
Le problème qui se pose à vous : bien sûr, vous ne pouvez voir qu'un seul film à la fois, mais vous aimeriez voir le maximum de films, tous vous intéressent
autant ( surtout le film ouzbek ).
Il va donc falloir faire des choix sur la liste des films à voir : quelle est la meilleure stratégie à adopter pour cela ?
Là aussi, l'étude de toutes les possibilités est impossible, vous allez donc adopter une stratégie gloutonne pour faire votre sélection.
La contrainte est que pour que deux films soient vus successivement, il faut qu'ils soient "compatibles", c'est à dire que leurs séances ne se "chevauchent" pas.
L'heure de début d'un film film doit suivre ( ou être égale à ) l'heure de fin du précédent ( par exemple, C8 et C10 sont compatibles, mais C13 et C15 ne le sont pas ).
La question est donc celle du critère à utiliser pour classer les films, et faire à chaque étape le meilleur choix pour le résultat global ( à savoir, voir le maximum de films ).
Plusieurs stratégies sont possibles pour classer les films :
...et ce, par ordre croissant ou décroissant ! Soit donc 6 possibilités, ça semble compliqué....heureusement, l'informatique va vous permette de résoudre votre problème !
Le séances seront représentées par un tuple (séance, début, fin); un tableau seances contiendra l'ensemble des tuples représentant les séances.
Vous trouverez ci-dessous une fonction affiche_seances, qui permet de visualiser un ensemble de séances :
Écrire 3 fonctions debut, fin, duree, qui serviront à trier, à l'aide de la méthode sort de Python, le tableau des séances selon les différents critères.
Tester les fonctions pour trier le tableau seances, sans oublier de tester les ordres ascendant et descendant.
Compléter le code de la fonction choix_seances ci-dessous, qui prend comme paramètres le tableau des séances trié selon un des critères ci-dessus, et qui renvoie le tableau des séances
compatibles pouvant être suivies, sélectionnées grâce à l'algorithme glouton ci-dessus.
Utiliser la fonction avec les différents critères de tri possible, et visualiser le résultat : quelles stratégies sont manifestement à éliminer ?
Pour départager les stratégies à adopter et trouver la meilleure, vous allez utiliser votre fonction avec une liste de séances beaucoup plus conséquente.
La fonction ci-dessous génère une liste de n séances d'heure et de début aléatoire, sur une plage de 24h.
Utiliser cette fonction pour déterminer quelle est la meilleure stratégie à adopter afin de voir le maximum de films !
On montre que, en plus d'être la meilleure stratégie gloutonne, ce mode de sélection conduit à la solution optimale du planning des séances : cet algorithme est donc vraiment utilisé pour faire des plannings.
Dans le même ordre d'idée, les algorithmes gloutons se montrent efficaces pour :