NSI Première
Les algorithmes de tri sont un domaine très important en informatique.
Tout d'abord c'est un problème algorithmique intéressant car on connaît sa limite théorique en complexité temporelle. L'objectif est donc toujours de se rapprocher au maximum de cette limite.
Mais ce n'est pas seulement un "jeu" informatique. En effet trier des données a de nombreuses applications :
Les algorithmes de tri sont aussi très utiles aux algorithmes de recherche comme la recherche par dichotomie que l'on a déjà vue.
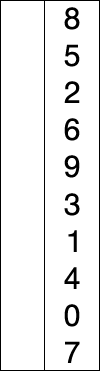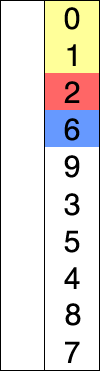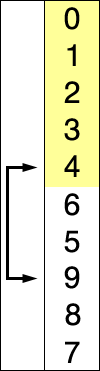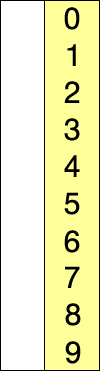
Dans l'exemple animé ci-contre, la case bleue parcours le tableau pour chercher le minimum, la case rouge correspond au minimum. Cette case rouge est ensuite déplacée pour construire la liste triée.
En gros, l'algorithme pourrait se traduire par :
pour chaque élément successif dans le tableau :
rechercher le minimum dans la suite du tableau
échanger ce minimum avec l’élément courant si il est plus petit que ce dernier
Plus précisément :
tri_selection(tableau t, n entier)
Entrées
t est un tableau non trié
n est la longueur de ce tableau
Sortie
le tableau t trié par ordre croissant
pour i variant de 0 à n - 1
mini ← i
pour j de i + 1 à n - 1
si t[j] < t[mini]
alors mini ← j
si mini est différent de i,
alors échanger t[i] et t[min]
renvoyer t
Le tri par sélection est un tri en place, ce qui signifie qu'il modifie ( = mute ) directement le tableau en entrée sans qu'il soit nécessaire d'en créer un autre.
Ceci est bien entedu possible car un tableau est justement un objet mutable; cela ne fonctionnerait bien entendu pas avec un tuple !
tri_selection() qui implémente l'algorithme précédent en Python, et testez-la sur le tableau L généré aléatoirement en l'affichant avant et après le tri.Nous allons maintenant tenter d'évaluer le coût en temps ( = complexité temporelle ) de cet algorithme.
Pour trouver un minimum dans un tableau de n éléments, il faut faire n comparaisons : la complexité en temps sera donc mesurée par le nombre total de comparaisons qu'il faudra faire pour trier entièrement le tableau.
Le tri insertion est assez proche du tri que l'on met en œuvre "naturellement" si l'on doit trier un ensemble de cartes.
Principe de cet algorithme :
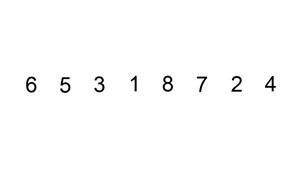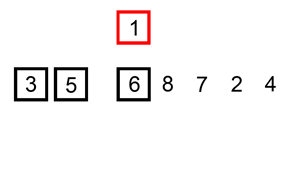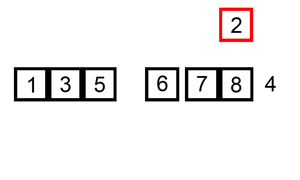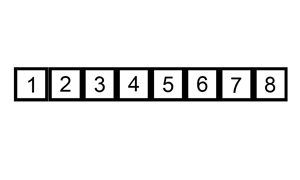
L'exemple animé ci-dessus, présente ce déroulement.
L'algorithme correspondant est donc le suivant :
pour chaque élément successif du tableau :
venir l'insérer à sa "bonne" place dans le début de la liste triée
Pour "placer l'élément i à sa bonne place", l'idée est de parcourir le début du tableau trié ( indices 0 à i-1 du tableau ), d'y rechercher la "bonne" place, de décaler vers la droite du tableau tous les éléments suivants pour "faire de la place", et d'insérer alors l'élément dans le "trou" ainsi créé.
Dans la pratique, pour trouver la "bonne" place, on va parcourir la partie triée du tableau du haut vers le bas ( donc de i-1 à 0 ), en décalant vers la droite les éléments triés tant que l'élément à placer est plus grand que les éléments en place : quand ce n'est plus le cas, on a trouvé la "bonne" place de l'élément, et on l'insère alors.
Ce mode de fonctionnement impose que l'on garde "en mémoire" l'élément à placer car il va se faire "écraser" par ces décalages vers la droite :
tri_insertion(tableau T, n entier)
Entrées
T est un tableau non trié
n est la longueur de ce tableau
Sortie
le tableau t trié par ordre croissant
pour i de 1 à n - 1:
temp ← T[i]
j ← i
tant que j > 0 et T[j - 1] > temp:
T[j] ← T[j-1]
décrémenter j
T[j] ← temp
renvoyer T
Le tri par insertion est donc aussi un algorithme de tri en place.
tri_insertion() qui implémente l'algorithme précédent en Python, et testez-la sur le tableau L généré aléatoirement en l'affichant avant et après le tri.Nous allons maintenant tenter d'évaluer le coût en temps ( = complexité temporelle ) de cet algorithme.
A chaque étape de l'algorithme précédent, on fait des comparaison pour placer l'élément courant à sa place dans la liste déjà triée : la complexité en temps sera donc là-aussi mesurée par le nombre total de comparaisons qu'il faudra faire pour trier entièrement le tableau.