Fusion de données en tables
Présentation d'un nouveau jeu de données
Vous avez sûrement remarqué que le fichier
countries.csv qui a servi à nos recherche précédentes ne contient pas le nom des capitales de pays.
En effet les villes sont répertoriées selon un code représenté par un entier.
On retrouve plus de 49000 viles dans le fichier
cities.csv dont voici un extrait de données :
id,nameCity,latitude,longitude,country,population
0,Sant Julià de Lòria,42.46372,1.49129,AD,8022
1,Ordino,42.55623,1.53319,AD,3066
2,les Escaldes,42.50729,1.53414,AD,15853
3,la Massana,42.54499,1.51483,AD,7211
4,Encamp,42.53474,1.58014,AD,11223
5,Canillo,42.5676,1.59756,AD,3292
6,Andorra la Vella,42.50779,1.52109,AD,20430
Clef commune aux deux jeux de données
Le champ
id du fichier
cities.csv correspond au champ
capital du fichier
countries.csv.
Nous dirons qu'il y a une
clef commune aux deux tables de données.
Dans le fichier cities.csv le champ id permet de différencier deux villes qui auraient le même nom. Chaque id n’apparaît qu'une fois dans le fichier, on parle dans ce cas de clef primaire.
Dans le fichier countries.csv, le champs capital est nécessairement pris dans les id du fichier cities.csv.
On parle dans ce cas de clef étrangère.
Construction d'une nouvelle table
On comprend bien que l'on aimerait enrichir les données propres aux pays avec celles contenues dans le fichier des villes (ou inversement).
Une des règle de construction des bases de données est de séparer au maximum les données pour ne pas gérer des tables trop lourdes.
Donc si les données sont séparées dans plusieurs tables, il est nécessaire de pouvoir construire, souvent uniquement pour le temps d'une recherche, une table à partir de deux tables séparées.
C'est que que l'on appelle
fusionner les tables.
Pour fusionner deux tables il faut donc:
- Le nom des deux tables
- Le nom des deux clefs qui serviront de critère de fusion
Fusion "à la main"
Pour bien comprendre le mécanisme de la fusion nous allons tout d'abord en faire une "à la main".
Pour cela nous disposons de deux courts extraits de données en tables :
- une table
LesActeurs.
- Une table
LesFilms.
et comme on peut s'en douter :
- Chaque film a une distribution composée d'acteurs
- Chaque acteur a une filmographie composée de films
Compléter "à la main" la fusion de ces deux tables sur le critère d'égalité lié au champ
film_id:
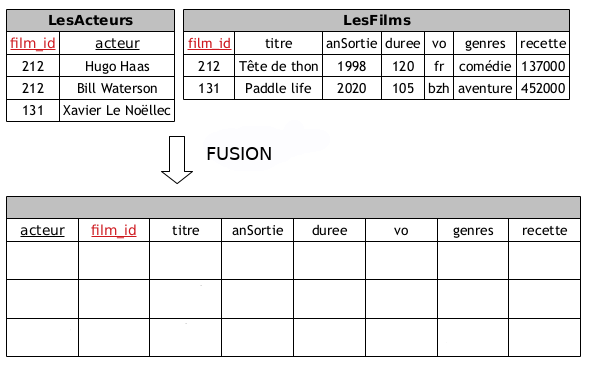 fusion de deux tables
fusion de deux tables
SOLUTION
Fonction de fusion en python
La fonction ci-dessous permet de fusionner les tables
table1 et
table2.
La fusion se fera sur les lignes dont :
la
valeur liée à la
cle1 dans
table1
et
la
valeur liée à la
cle2 dans
table2
sont égales.
contrairement à ce que l'on a pût faire dans l'exemple "à la main", les deux clefs deux deux données en tables n'ont pas nécessairement le même nom, d'où l'existence de deux variables cle1 et cle2.
def fusion(table1, cle1, table2, cle2):
fusion=[]
for element1 in table1:
for element2 in table2:
if element1[cle1]==element2[cle2]:
element_fusion=element1
for clef in element2:
element_fusion[clef]=element2[clef]
fusion.append(element_fusion)
return fusion
- Fusionner les tables issues des fichiers
countries.csv et cities.csv en ajoutant à chaque pays toutes les caractéristiques de sa capitale
- Afficher le premier élément de cette table fusionnée.
- Quelle redondance apparaît dans cette table ?
- Ajouter une ligne dans la fonction
fusion() pour éviter cette redondance.
- Une fois la modification réalisée, fusionner à nouveau les tables puis afficher le premier élément de cette table fusionnée pour vérifier que la redondance est bien absente.
# codez ces questions ici
SOLUTION
Recherche dans une table issue d'une fusion
Nous allons maintenant exploiter cette notion de fusion de table pour effectuer des recherches :
- Afficher toutes les capitales dans lesquelles on peut dépenser des Euros
- Afficher le nom des pays dont la capitale a moins de 100 000 habitants
- Afficher le nom des pays dont la capitale est située entre les deux tropiques (de latitudes -23.436° et +23.436°)
# codez ces questions ici
SOLUTION
Nous avons vu dans cette partie que la gestion des données en tables entraîne des problèmes :
- d'indexation
- de recherche
- de tri
- de fusion
- ... et il en existe encore bien d'autres...
On a également pu constater que l'accumulation de ces problèmes peut être résolu par des codes python assez lourds.
Il existe d'autres façons de résoudre ces problèmes :
- Utiliser une bibliothèque python adapté à ce genre de problème (par exemple
pandas)
- parler ici SGBD ssytèles inétgrés et SQL