Implémentation Python des algorithmes de parcours de graphes
Algorithmes BFS et DFS
Vous allez maintenant implémenter les algorithmes vus au chapitre précédent.
Préalablement, il faudra que vous disposiez des ressources vous permettant de gérer un graphe bien sûr, mais également les structures de données ( pile et file ) nécessaires aux parcours.
- Pour les graphes : une implémentation sous forme de matrice d'adjacence serait mal adaptée ( pourquoi ?? )...
- Pour la file : vous avez plusieurs possibilités, qui utilisent toutes le paradigme de programmation objet :
- soit utiliser une implémentation réalisée par vous-même ( liste Python, qui présente des limitations en terme d'efficacité, même si a priori ici, les files ne seront jamais très grandes , ou version file avec deux piles que vous aviez faite en exercice, ou file circulaire, optimisée, etc...)
- la classe
deque, que vous avez déjà utilisée pour le parcours en largeur des arbres.
- Pour la pile : là-aussi, plusieurs solutions :
- une classe écrite par vous-même, qui utilise une liste Python ou une liste chaînée ( donc de bonne efficacité puisque n'utilisant que les méthodes de liste Python
pop()etappend()qui sont en O(1). ) - la classe
deque
- une classe écrite par vous-même, qui utilise une liste Python ou une liste chaînée ( donc de bonne efficacité puisque n'utilisant que les méthodes de liste Python
Les deques sont une généralisation des piles et des files ( deque se prononce "dèque" et est l'abréviation de l'anglais double-ended queue) : il est possible d'ajouter et retirer des éléments par les deux bouts des deques. Celles-ci gèrent des ajouts et des retraits utilisables par de multiples fils d'exécution (thread-safe) et efficaces du point de vue de la mémoire des deux côtés de la deque, avec approximativement la même performance en O(1) dans les deux sens.
Il faut importer la classe deque à partir du module collections :
from collections import deque
Pour créer une deque vide :
pile = deque() # ou file = deque() bien sûr...
Il existe plusieurs méthodes pour ajouter/retirer des éléments à chaque "extrémité" d'une deque :
| A gauche | A droite | |
|---|---|---|
| insertion d'un élément | appendleft(x) |
append(x) |
| suppression et renvoi d'un élément | popleft() |
pop() |
Chaque extrémité d'une deque étant parfaitement équivalente en terme de complexité, à vous de choisir les méthodes adaptées pour la gestion de votre file ou de votre pile.
Enfin, la fonction len() peut être appliquée à une deque pour déterminer le nombre d'éléments qu'elle contient.
len(pile) # renvoie le nombre d'éléments dans la deque
Dans un script qui importe tous les modules nécessaires, écrire le code des fonctions suivantes, puis les tester sur les graphes donnés en exemple.
Ici, "traiter un sommet" consistera soit à simplement afficher son étiquette, soit à remplir ( par exemple ) un tableau avec les étiquettes des sommets, tableau qui sera renvoyé en fin de parcours pour visualiser celui-ci.
Du parcours de graphe en profondeur d'abord récursif :
Attention à la nécessité de passer comme paramètre la structure de données gardant la trace des sommets déjà visités; étant mutable, cette structure devra être initialisée en dehors de la fonction.
Du parcours de graphe en profondeur d'abord ( DFS ) itératif :
Attention à marquer le sommet de départ comme visité avant le parcours des autres sommets.
Du parcours de graphe en largeur d'abord ( BFS ) :
Applications
Existence d'un chemin
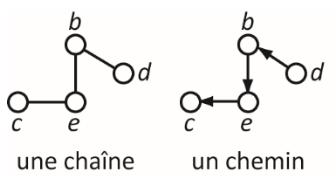
Un chemin dans un graphe orienté est une succession d'arcs qui permet d'aller d'un sommet à un autre;
Dans un graphe non-orienté, une telle succession d'arêtes est appelée une chaîne.
Mais pour simplifier nous utiliserons le terme "chemin" aussi bien dans le cas des graphes orientés ou non; et plus précisément, nous chercherons des chemins élémentaires, c'est à dire qui ne passent pas deux fois par le même sommet.
Principe
Comment déterminer si il existe un chemin élémentaire entre deux sommets, et surtout, quel est alors ce chemin ? Voila un problème qui se rencontre par exemple dans la recherche de la sortie d'un labyrinthe ( ce sera traité en application.), ou alors savoir si un routeur donné dans un réseau est accessible de tous les autres.
Le parcours en profondeur permet de trouver un chemin entre deux sommets ( dont l'un constitue la racine du parcours ) : en effet, il suit les sommets de voisins en voisins, et "revient en arrière" si il aboutit à une impasse pour "repartir" d'un nouvel embranchement ( c'est pourquoi on parle parfois de bactracking ou retour en arrière pour cet algorithme ).
Attention, l'algorithme permet simplement de savoir si un chemin existe entre deux sommets, ce n'est pas forcément le plus court !
Le problème est que le parcours du graphe ne garde pas la trace des sommets sur le chemin à suivre : le parcours explore tous les sommets du graphe, mais on ne voudrait "garder" que ceux "que l'on ne visite qu'une seule fois"...
Pour cela, il va donc falloir, pour chaque sommet visité, stocker ( par exemple dans un dictionnaire, initialisé comme vide ) le prédécesseur dans le parcours du graphe de ce sommet, c'est à dire le "sommet ( unique) d'où l'on vient" pour chaque sommet visité; ce dictionnaire aura même deux rôles :
- on pourra, en "remontant" la liste des prédécesseurs jusqu'au début du parcours, "reconstituer" le chemin à suivre.
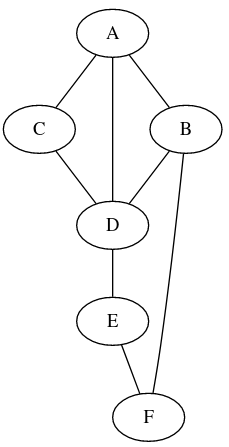
Par exemple, dans le graphe ci-contre, le dictionnaire des prédécesseurs associé à un parcours en profondeur depuis le sommet 'A' est :
pred = {'A': None, 'B': 'A', 'C': 'A', 'D': 'A', 'E': 'D', 'F': 'E'}A partir de ce dictionnaire, on peut alors "reconstruire" n'importe quel chemin depuis le sommet 'A', en partant du sommet de fin puis en remplaçant progressivement un sommet par son prédécesseur.
Par exemple, pour le chemin de 'A' à 'F' :'A' -> 'D' -> 'E' -> 'F'( non, ce n'est pas forcément le plus court chemin...)
- Ce dictionnaire remplacera également la structure mémorisant les sommets déjà visités ( le tableau visites des implémentations de parcours précédentes ) : un sommet qui n'est pas dans le dictionnaire n'a donc pas encore été visité...
Dans ce dictionnaire, le sommet de départ du parcours aura bien entendu None comme prédécesseur.
Si on parcourt le graphe dans son intégralité, alors ce dictionnaire permettra de déterminer tous les chemins depuis le sommet de départ jusqu'à chacun des sommets du graphe; cependant, si un seul chemin est recherché, on peut alors arrêter le parcours dès que l'on a visité le sommet de fin.
Si à la fin du parcours, on n'a pas visité le sommet de fin, c'est donc que le chemin n'existe pas...
Utilisation du parcours en profondeur pour trouver un chemin
Écrire une fonction cherche_chemin qui renvoie le dictionnaire des prédécesseurs pour un parcours entre deux sommets quelconques depart et fin d'un graphe si un chemin existe
effectivement.
Une fonction pour reconstruire un chemin
On suppose maintenant disposer du dictionnaire des prédécesseurs complet ( donc, à la fin du parcours ); le chemin sera alors déterminé à partir de ce dictionnaire à l'aide d'une fonction annexe
chemin.
Le chemin sera renvoyé sous la forme d'une liste des sommets à suivre depuis le départ jusqu'à la fin du chemin : ['A', 'D', 'E', 'F']
Écrire cette fonction, et la tester avec un dictionnaire simple.
Cette fonction peut être codée très simplement sous forme récursive ! Comme d'habitude, réfléchir à son cas de base et à son cas général...
Recherche et affichage
Utiliser maintenant les deux fonctions conjointement pour vérifier que la recherche
du chemin est effective dans le graphe de l'exemple de ce paragraphe.
Utiliser également ces fonctions pour montrer qu'un chemin existe dans le deuxième graphe entre les sommets 'A' et 'E', mais pas entre 'A' et 'F'.
Plus court chemin entre deux sommets
Voila un autre problème, mais vous allez voir que ce n'est pas beaucoup plus compliqué...
Vous imaginez bien : cette fois-ci, c'est le parcours en largeur qui va permettre de résoudre ce problème.
En effet, le parcours en largeur parcourt les sommets du graphe en "s'éloignant" progressivement de la racine du parcours; lorsqu'on rencontre le sommet d'arrivée, on est donc assurés d'avoir parcouru le plus petit nombre d'arêtes/arcs.
On doit cependant là aussi garder la trace des sommets à parcourir, c'est pourquoi le stockage des prédécesseurs de chaque sommet dans le parcours sera également nécessaire.
Écrire une fonction plus_court_chemin de façon à ce qu'elle renvoie le plus court chemin entre deux sommets quelconques, en
utilisant également la fonction annexe de reconstruction du chemin.
L'algorithme trouve-t-il cette fois bien le plus court chemin ?
- recherche d'un chemin → parcours en profondeur
- recherche du plus court chemin → parcours en largeur
Pourquoi ne pas toujours utiliser le parcours en largeur pour trouver un chemin dans un graphe, puisque celui-ci nous donne en plus le plus court des chemins ( si il existe bien entendu ) ?
Il faut voir que le parcours en largeur parcours tous les sommets du graphe en "s'éloignant" progressivement du sommet de départ; dans un très grand graphe, il peut se passer un moment avant que l'on ne "tombe" sur le sommet d'arrivée si celui-ci se trouve très éloigné du départ.
Le parcours en profondeur "explore" au contraire un chemin en suivant toutes les possibilités jusqu'à aboutir à une "impasse", auquel cas il "retourne en arrière" pour "explorer une nouvelle piste"; il y a donc beaucoup plus de chances que l'on tombe ainsi plus rapidement sur le sommet d'arrivée, dans la mesure bien sûr où le chemin existe...
Il existe des algorithmes de recherche de plus court chemin plus efficaces que BFS, mais si la seule recherche de l'existence d'un chemin suffit, alors DFS peut suffire...
Détermination de la présence d'un cycle/d'un circuit
Un graphe non orienté présente un cycle si il existe une suite d'arêtes, une chaîne, dont le sommet de début et de fin est le même.
Dans le cas d'un graphe orienté, une telle suite d'arcs est appelée un circuit.
La recherche de la présence d'un cycle dans un graphe permet de détecter, par exemple, des situations où des informations tourneraient "en boucle" dans un réseau, et optimiser celui-ci, ou alors transformer le graphe en arbre ( qui est, on le rappelle, un graphe orienté acyclique ).
Le principe est simple : il faut chercher si il existe dans le graphe un chemin entre le sommet de départ...et lui-même !
Dans la pratique, à partir d'un de ses sommets, on parcourt le graphe ( en largeur ou en profondeur, peu importe..), et si en un point du parcours, on "retombe" sur
le sommet de départ ( graphe orienté ) ou un sommet déjà visité ( graphe non-orienté ), alors le graphe comporte effectivement un cycle.
Cependant, dans un graphe orienté, ou non-orienté mais pas ( complètement ) connexe, il peut y avoir des sommets "non-accessibles" selon le sommet duquel on commence le parcours, et la recherche d'éventuels cycles ne sera donc pas exhaustive : il faut donc recommencer le parcours depuis tous les sommets ( dans l'idéal, il faudrait en fait faire le parcours de toutes les composantes connexes du graphe, mais la détermination de celles-ci n'est pas au programme. Alors, tant pis pour le O(n²) 😌...).
Circuit dans un graphe orienté
Dans ce cas, l'algorithme est très simple : c'est une simple adaptation de la recherche d'un chemin entre deux sommets; à chaque "découverte" d'un nouveau sommet, on teste simplement si il a déjà été visité : si c'est le cas, et si ce sommet est celui de départ, alors on a détecté un circuit ; dans le cas contraire, on continue le parcours :
pour chaque sommet v adjacents du sommet courant
si v n'a pas encore été visité:
marquer le sommet v comme visité
continuer le parcours à partir de v
sinon, si on est revenu au sommet de départ:
on a détecté un circuit !
Il serait également intéressant d'afficher le circuit au cas où celui-ci est détecté.
Pour cela, on peut lors de la recherche de circuit, remplir un dictionnaire des prédécesseurs comme cela a été fait dans la recherche de chemin.
Combiné à la fonction de "reconstruction" d'un chemin, ceci permettra d'identifier le circuit détecté dans le graphe.
- écrire une fonction
cherche_circuit, qui :- prend comme paramètre un graphe et le sommet de départ
- renvoie le dictionnaire des prédécesseurs de chaque sommet si un circuit est détecté,
Nonesinon.
pred = {'B': 'E', 'K': 'B', 'H': 'K', 'I': 'K', 'F': 'I', 'G': 'F', 'E': 'G', 'J': 'G'} - En adaptant la fonction de "reconstruction" d'un chemin à partir du dictionnaire des prédécesseurs, écrire une fonction
affiche_circuitqui renvoie le tableau des sommets représentant un circuit. - Utiliser les 3 fonctions avec les 2 graphes cycliques donnés en exemple pour vérifier le bon fonctionnement de votre implémentation.
Cycle dans un graphe non-orienté
Dans ce cas, l'approche est un peu différente : on détecte un cycle si, au cours du parcours, on rencontre simplement un sommet déjà visité.
Mais il y a une contrainte : dans un graphe non orienté, un sommet déjà visité peut être le prédécesseur direct du sommet en cours de visité; ce prédécesseur est alors aussi un voisin du sommet en cours de visite : on détecterait alors faussement un cycle...
L'idée est, à toute étape de l'algorithme, de justement "garder la trace" du prédécesseur de chaque sommet en cours de visite, pour ne pas le tester comme départ d'un éventuel cycle.
Si en un point de l'algorithme, on rencontre un sommet déjà visité, mais qui n'est pas le prédécesseur du sommet courant, alors on aura détecté un cycle :
Pour cela, on pourra par exemple enfiler/empiler un tuple constitué du sommet et de son prédécesseur
tant que la file/la pile n'est pas vide:
defiler/dépiler (u, pred)
marquer le sommet u comme visité
pour tous les sommets v adjacents de u:
si v n'a pas encore été visité:
empiler/enfiler (v, u)
sinon ( ⇔ v a déjà été visité ), si v n'est pas le prédécesseur de u:
renvoyer le cycle !
on n'a pas trouvé de cycle : renvoyer None
Au début du parcours, on enfilera/empilera None comme prédécesseur du sommet de départ.
- écrire une fonction
cherche_cycle, qui :- prend comme paramètre un graphe non orienté et un sommet de départ
- renvoie le dictionnaire des prédécesseurs de chaque sommet si un cycle est détecté,
Nonesinon.
- Utiliser alors la fonction
contient_cycle, qui prend un graphe en paramètre, recherche la présence d'un cycle, et affiche le cycle au cas où celui-ci existe dans le graphe
Cette fonction utilisera une fonctionaffiche_cycleadaptée de la fonctionaffiche_circuit.
Distances entre deux sommets
Algorithmes pas au programme officiel. Ce sont des "prolongements" de l'algorithme du parcours en largeur.
Plus petite distance en nombre d'arcs/d’arêtes
La plus petite distance entre deux sommets d’un graphe est la longueur du plus petit chemin possible entre ces deux sommets. Dans un graphe non pondéré, elle est donc égale au nombre minimal d'arêtes/d'arcs à parcourir entre les deux sommets.
Dans le parcours en largeur, on "s'éloigne" petit à petit de la racine du parcours. En tenant le compte du nombre de "niveaux" dont l'algorithme s'est "éloigné" depuis la racine, il permet donc de déterminer la distance entre la racine du parcours et chaque sommet du graphe.
Ceci est une simplification de l'algorithme plus général appelé algorithme de Dijkstra, qui calcule les distances d'un sommet donné à tous les autres dans un graphe pondéré.
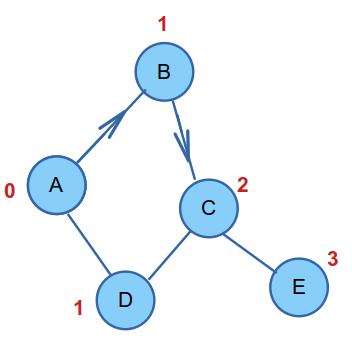
Le dictionnaire des prédécesseurs sera remplacé par un dictionnaire des distances de chaque sommet depuis le sommet de départ du parcours, que l'on remplira au fur et à mesure de la visite des sommets, moment où on calculera leur distance..
Dans ce dictionnaire, le sommet de départ sera donc à la distance 0 de lui-même !
Le principe : on réalise donc un parcours BFS du graphe depuis un sommet de départ.
Pour chaque sommet pas encore visité, on calcule sa distance depuis le sommet de départ : on alors a parcouru une arête/un arc de plus depuis le prédécesseur du sommet; la distance de
ce sommet depuis le départ du parcours est donc égale à celle de son prédécesseur augmentée de 1.
- a quel moment de l'algorithme change-t-on de "niveau d'exploration" en passant au niveau "suivant" ?
- que faut-il alors modifier dans l'algorithme BFS pour calculer la distance de chaque sommet en cours de visite depuis le sommet de départ du parcours ?
- écrire une fonction
calcule_distancesqui calcule les distances de chaque sommet du graphe à un sommet de départ du parcours. - tester la fonction sur les graphes proposés.
- écrire une fonction
cherche_distance, qui renvoie la distance entre deux sommet quelconques du graphe ( il faut bien sûr qu'un chemin existe entre ces deux sommets ! )
Plus petite distance dans un graphe pondéré
Dans ce cas, on part du principe que, par exemple, le "poids" d'un arc/d'une arête représente la distance entre deux sommets : plus le poids est grand, plus cette distance est élevée.
La situation est plus délicate à traiter : en effet, si il y a plusieurs chemins pour aller jusqu'à un sommet donné, leurs longueurs cumulées ne sont généralement pas les mêmes; il va alors falloir dans ce cas pouvoir déterminer laquelle est la plus petite...
Une "vraie" recherche du plus court chemin doit donc tenir compte de la distance cumulée depuis le début du parcours.
L'algorithme de Dijkstra
Pour cela, l'algorithme de Dijkstra ( hors programme ) utilise une structure de données appelée file à priorité ( FAP ) pour stocker, puis sélectionner, pour chaque sommet, l'arête/arc de plus faible "poids" dans la longueur totale du chemin à suivre d'un sommet aux autres sommets d'un graphe :
Cet algorithme est étudié en détails ailleurs dans ce cours dans le contexte du routage sur un réseau.
C'est donc un parcours en largeur d'un graphe pondéré avec recherche du plus court chemin; cet algorithme donne un résultat optimal, mais peut être très lent sur de (très) grands graphes.
Algorithme
- On initialise les distances (« distances ») de tous les sommets à l’infini : on n’a aucune information les concernant
- On met le sommet de départ à une distance 0 puisque l’on part de ce sommet
- On n’a visité aucun sommet, donc on crée une liste de sommets visités vide
- Tant qu’il y a des distances infinies dans les sommets non visités (pour être sûr de ne pas manquer le chemin le plus court) :
- On détermine le sommet le plus proche, non visité, du sommet où on est et on le visite
- pour chaque voisin du sommet où on arrive :
- on compare la distance déjà calculée depuis le sommet de départ, avec la distance obtenue si on passe par le sommet où l’on est
- Si la distance, en passant par le sommet où l’on est, est plus petite que la distance en mémoire, on la met à jour pour obtenir la plus petite distance possible
- On marque le sommet comme visité
- On retourne la liste des distances (« distances »)
Une implémentation en Python peut être trouvée ici.
Autres algorithmes du plus court chemin
Une amélioration de l'efficacité de l'algorithme de Dijkstra est l’algorithme A* ( "A-star" ), qui utilise une heuristique pour déterminer à chaque étape, la "direction" vers laquelle aller
pour atteindre le sommet d'arrivée.
Cet algorithme ne donne pas forcément un résultat optimal, mais est beaucoup plus rapide; c'est celui qui est utilisé comme IA dans de nombreux jeux.