TP : arbres de décision
Ou voir qu'un arbre n'est pas forcément binaire !...
Introduction
Dans un processus de décision, c'est à dire décider de la réponse à apporter à un problème donné, un arbre de décision permet de représenter "l'enchaînement" des différents choix à faire pour arriver à une décision donnée : par exemple, les différents coups à jouer pour gagner une partie d'échecs, les critères à vérifier pour décider quel type de maladie un patient a, les critères d'admission d'un étudiant dans une filière donné, etc...
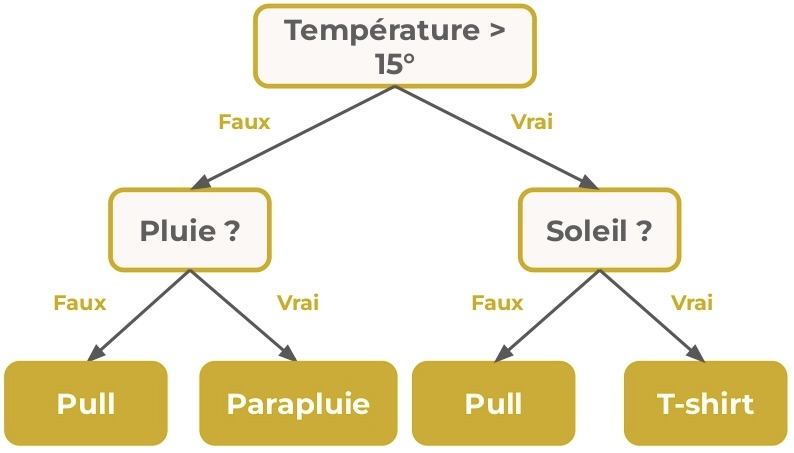
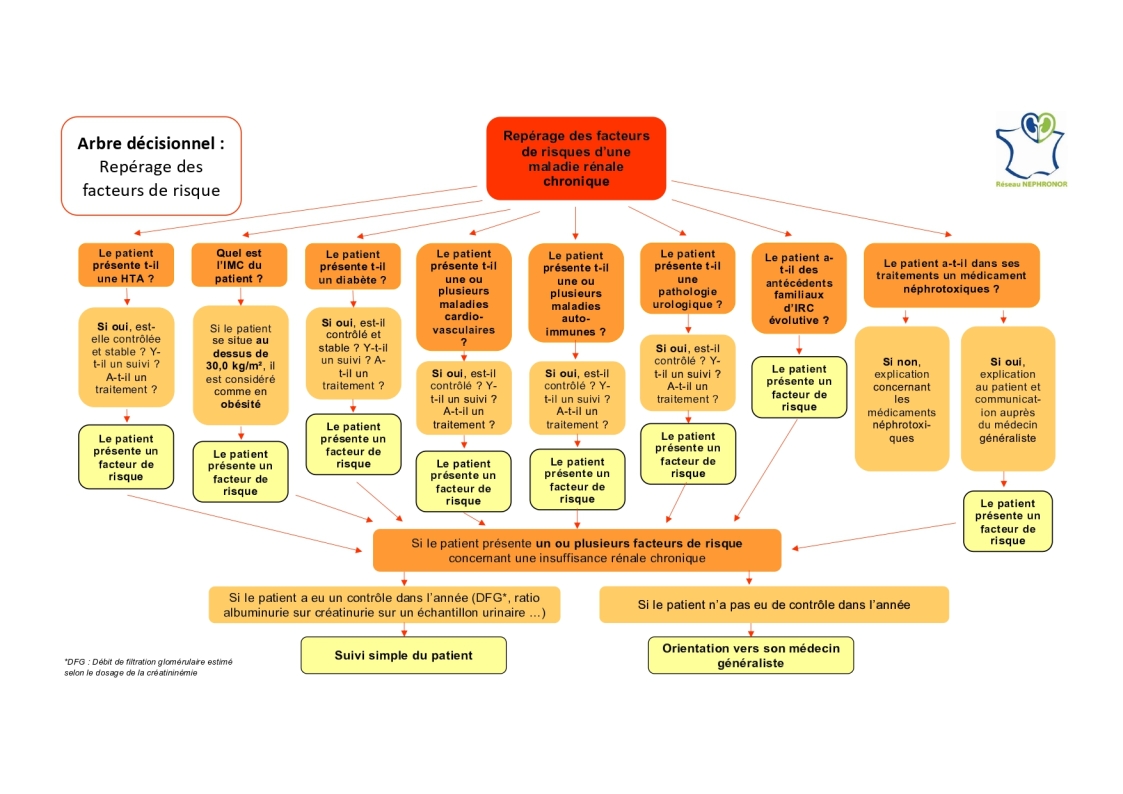
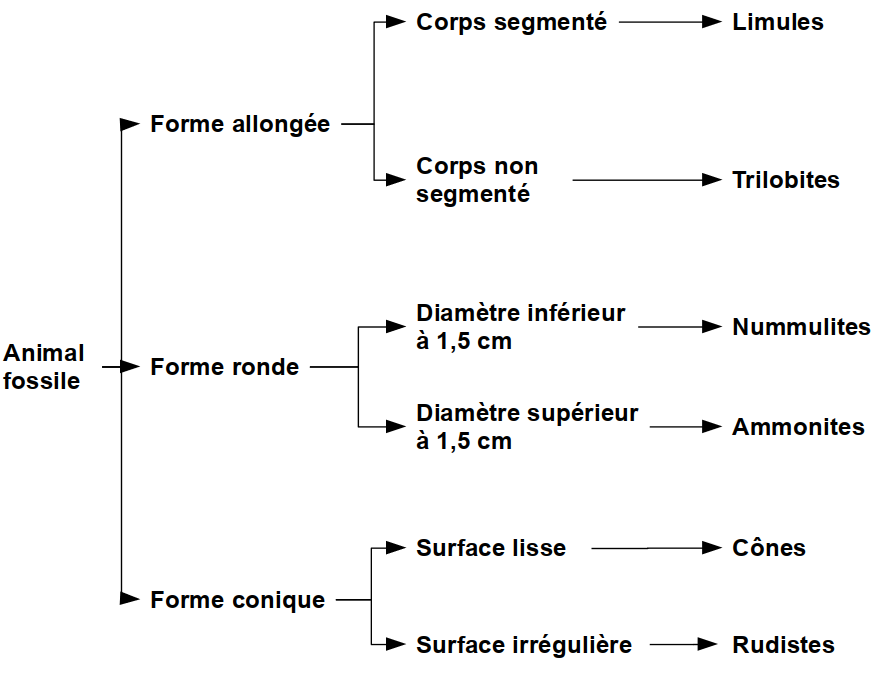
Un arbre de décision n'est donc pas forcément binaire, et le degré de tous ses nœuds n'est pas non plus forcément le même.
- Les nœuds internes de l'arbre correspondent aux critères testés à chaque étape du processus de décision,
- les branches aux choix de la valeur de ces critères,
- les feuilles à la décision finale.
Il existe des arbres de décision qui manipulent des critères continus, c'est à dire qui peuvent prendre n'importe quelle valeur: les algorithmes de création de tels arbres sont délicats à mettre en œuvre, vous ne travaillerez donc ici qu'avec des arbres basés sur des critères discrets, c'est à dire qui ne peuvent prendre qu'un nombre fini de valeurs.
Utilité
Les arbres de décision sont utilisés notamment en apprentissage automatique supervisé ( = machine learning ) dans le cadre de la fouille de données ( = data mining ) pour classifier des données, c'est à dire "ranger" des données dans des ensembles homogènes ( = des classes ), comme par exemple toutes les images qui contiennent un animal, toutes celles qui montrent un ciel bleu, etc...
Une fois un arbre de décision construit, il pourra alors être utilisé pour déterminer à quel classe appartient une donnée de classe inconnue : cette image contient-elle un animal ? du ciel bleu ? ...
On obtient dans ce cas un arbre de classification ( il existe aussi des arbres de régression, non étudiés ici ).
Algorithmes d'apprentissage
La création d'un arbre de décision nécessite des données d'apprentissage, dans lequel est associé une décision à une suite de choix suivis; cet ensemble doit être suffisamment grand pour qu'un algorithme d'apprentissage puisse en faire une analyse statistique afin d'en tirer les "règles" générales qui aboutissent à telle ou telle décision.
Dans un processus de décision, il faut à chaque étape faire un choix sur un critère à tester ; cependant, chaque critère n'a pas la même importance dans le processus de décision : pour l'affectation d'un étudiant dans une filière informatique, le premier critère à tester est bien sûr si l'étudiant à suivi la spécialité NSI en Terminale; si oui, on regardera ensuite sa moyenne dans la spécialité, si non, on regardera si il a suivi une autre spécialité scientifique,...et ainsi de suite jusqu'à la décision ( ou non ! ) d'affectation.
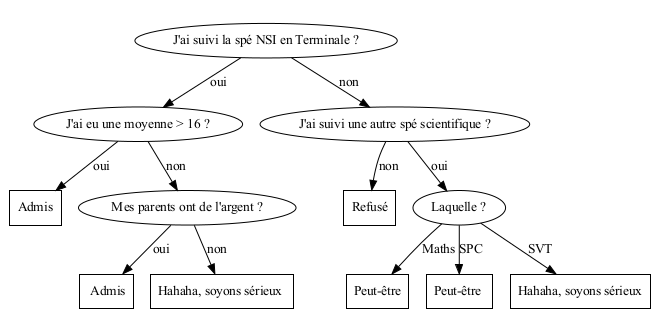
L'algorithme d'apprentissage va être chargé de faire automatiquement ces choix pour construire l'arbre de décision à partir des données d'apprentissage; le problème est alors : comment, dans un ensemble de critères, faire choisir à un algorithme le "meilleur" à tester à chaque étape ?? C'est celui qui "pèsera" le plus à ce moment dans la décision finale, c'est à dire celui qui apportera le plus d'information à cette étape de l’algorithme dans la décision finale : comment peut-on bien mesurer cela ??? 😶
L'algorithme ID3 = Iterative Dichotomiser 3 )
Parce qu'il est simple à comprendre et à étudier, vous allez essayer d'implémenter l'algortihme ID3 développé par Ross Quinlan en 1986.
Cet algorithme se sert d'une grandeur appelée entropie d'un ensemble pour déterminer à chaque étape le "meilleur" critère à étudier.
Entropie d'un ensemble
L'entropie est une grandeur physique qui mesure le degré de désordre d'un système : plus l'entropie d'un système est grande, plus le système est désordonné.
Claude Shannon a adapté ce concept à celui d'entropie d'un ensemble de données.
Ce n'est pas une notion évidente ( vous pouvez lire cette page pour plus d'informations ), mais retenez que plus l'entropie d'un ensemble de données est grande, plus la quantité d'informations que ces données "contiennent" est importante.
De manière générale, l'entropie se calcule avec une relation faisant intervenir des probabilités; une fonction vous sera donnée qui permet le calcul de cette grandeur.
A lire par ceux qui veulent en savoir un peu plus ( pas indispensable pour la suite ).
Que mesure vraiment l'entropie d'un ensemble ?
Voila un premier exemple : vous savez, bien entendu, qu'avec n bits, on peut coder au maximum N = 2n valeurs; inversement, on montre alors que pour coder une valeur N quelconque, il faut log2(n) bits : pour coder une valeur de 255 par exemple, il faut n = log2(255) = 8 bits.
Pour un ensemble de nombres quelconques, tous inférieurs ou égaux à N, ce nombre de bits représente alors la quantité minimale d'informations à connaître pour déterminer sans ambiguïté la valeur d'un nombre dans cet ensemble ; c'est ce que l'on appelle l'entropie de cet ensemble de nombre,
Plus n est grand, plus l'ensemble pourra être constitué de valeurs différentes, et donc plus l'ensemble sera "désordonné", ce qui signifie qu'il contiendra aussi une quantité d'informations différentes plus grande.
On a dit au dessus que le calcul de l'entropie d'un ensemble est lié aux probabilités; dans l'exemple précédent, chaque nombre binaire aurait la même probabilité d'apparaître dans un ensemble de ces nombres, mais prenons en deuxième exemple le lancer d'une pièce : pour une pièce non truquée, on a une probabilité de 1/2 de faire aussi bien un "pile" qu'un "face"; pour un ensemble de lancers de cette pièce, cet ensemble est désordonné au maximum, ce qui se traduit ici par une incertitude maximale sur le résultat d'un lancer donné ( il faudrait une infinité d'informations pour pouvoir le prévoir ! ) On peut calculer cette entropie, on trouve alors une valeur de 1.
Par contre, avec une pièce truquée, qui donnerait par exemple "pile" dans 60% des cas et "face" dans 40%, on a plus d'informations sur un futur lancer, donc moins d'incertitude : un ensemble de lancers de cette pièce sera beaucoup plus ordonné, et son entropie plus faible ( on montre qu'elle est de 0,93 ).
Dans le cas extrême où la pièce a deux côtés "pile" ( ou deux côtés "face" ), l'entropie d'un ensemble de lancers est égale à 0 : cet ensemble est complètement ordonné, il n'y aucune incertitude sur le résultat d'un lancer donné !
Gain d'informations
Dans le cadre de l'algorithme ID3, on calcule alors à chaque étape, et pour chacun des critères "candidats" à cette étape, le gain d'information ( ou perte d'entropie ) qu'apporterait ce critère :
- on "scinde" l'ensemble des données en sous-ensembles pour lequel le critère prend une valeur particulière ( parmi les valeurs possibles pour ce critère )
- on calcule l'entropie de chacun de ces sous-ensembles
- on calcule alors le gain d'information que l'on obtiendrait en scindant l'ensemble des données selon ce critère : ce gain est égal à l'entropie de l'ensemble de données, moins les entropies des sous-ensembles.
Plus le gain d'information est grand ( plus on a perdu d'entropie ), plus le critère "pèsera" dans le résultat final, car cela signifie que l'on aura "exploité" le plus grand nombre d'informations en testant ce critère.
Le critère testé ayant le plus grand gain d'information est le "meilleur" à considérer à cette étape de l'algorithme : on scinde alors effectivement l'ensemble des données selon ce critère, et on recommence récursivement la recherche du meilleur critère sur chaque sous-ensemble de données.
Quand on arrive à un sous-ensemble dont l'entropie est nulle, on sait qu'on a exploité toutes les informations qu'apportait cette succession de critères : on arrête alors la récursion, car tous les exemples appartiennent alors à la même classe.
Là aussi, une fonction vous sera donnée pour calculer le gain d'information d'un ensemble selon un critère de test donné.
Un peu de vocabulaire :
- un attribut correspond à un critère dans le processus de décision
- un exemple est une suite de choix, c'est à dire de résultats de tests sur un ensemble d'attributs.
- l'étiquette d'un exemple est la "valeur" du résultat de cet exemple. Un exemple étiqueté est un exemple dont on connaît déjà l'étiquette, et est obtenu grâce aux données d'apprentissage; un exemple non étiqueté est au contraire un exemple dont on déterminera l'étiquette grâce à l'arbre de décision.
- une classe représente un ensemble homogène d'exemples, c'est à dire qui ont tous la même étiquette ( ils mènent donc tous à la même décision ).
L'entropie d'une classe est donc nulle ( les exemples d'une même classe mènent tous au même résultat, comme les lancers de la pièce truquée à deux mêmes faces..)
Vous allez travailler dans ce TP sur la situation utilisée par l'auteur de l'algorithme pour présenter celui-ci, dans le but de créer l'arbre de décision répondant à la question : Selon la météo ( attributs temps, température, humidité, et vent), vais-je aller jouer au tennis ?
Voici les données d'apprentissage de cette étude :
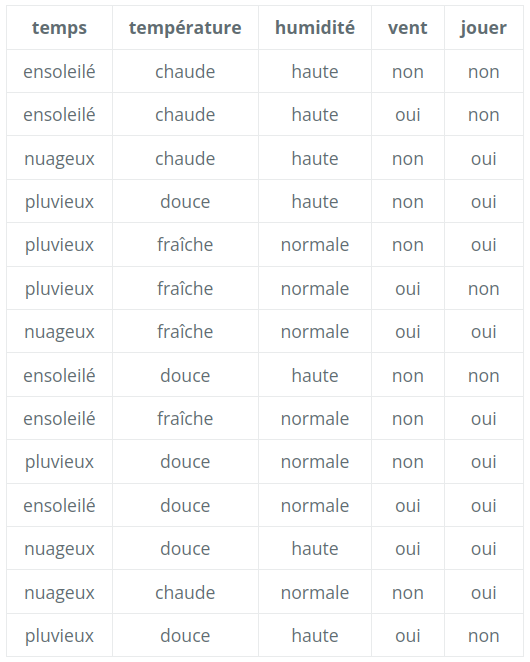
Les attributs des exemples sont les titres de la première ligne de ce tableau, sauf celui de la dernière colonne qui correspond à leur étiquette.
Chaque ligne du tableau correspond à un exemple d'entraînement ( ce sont donc tous des exemples déjà étiquetés ).
Il y a deux classes dans les exemples, la classe "OUI" et la classe "NON". Ce sont les valeurs possibles pour l'étiquette.
Déroulement de l'algorithme
ID3 est donc un algorithme récursif on l'a dit, mais c'est aussi un algorithme glouton ( pourquoi ?? ) :
FONCTION ID3
Entrée :
- exemples = liste d'exemples étiquetés
- attributs = liste des attributs non utilisés jusqu'à présent
Retour :
- un nœud
# cas de base : on est arrivés à une décision finale ( une feuille )
# dans ce cas, les exemples appartiennent donc à la même classe ( = ils ont la même étiquette )
SI tous les exemples appartiennent à la même classe, alors
Renvoyer une feuille ayant cette classe
FIN SI
# si la liste des attributs à tester est vide,
# on crée une feuille ayant la classe la plus fréquente
# dans les exemples restant
SI la liste des attributs à tester est vide,
Renvoyer une feuille de la classe la plus fréquente dans les exemples restants
FIN SI
# recherche du "meilleur" attribut à cette étape
q = attribut optimal dans la liste attributs
SI il n'y a pas d'attribut optimal ( ils donnent tous le même gain d'information !)
Renvoyer une feuille de la classe la plus fréquente dans les exemples restants
FIN SI
n = nouveau nœud créé pour l'attribut q
on retire q de la liste attributs ( inutile de le retester par la suite )
POUR chaque v = valeur possible de q :
e = l'ensemble des exemples pour lesquels l'attribut q a la valeur v
chaque nœud fils de n est créé récursivement par ID3(e, attributs)
FIN POUR
Renvoyer n
FIN
On remarque que si tous les attributs apportent le même gain d'information, plutôt que d'en choisir un au hasard, on préfère alors considérer que les attributs restants ne sont pas déterminants pour la décision, que l'on suppose alors être celle de la classe la plus fréquente dans les exemples qui restent; c'est un choix...
En cours d'algorithme, la liste des attributs à tester peut devenir vide alors qu'il reste des exemples à étiqueter, si dans les données apparaissent des exemples identiques mais dont la classe
n'est pas la même, par exemple, deux mêmes exemples dont l'un conduit à "OUI" et l'autre à "NON". Dans des données réelles, ce genre d'incohérence peut se produire souvent !
Dans ce cas, on n'a pas le choix que de choisir la classe la plus fréquente dans les exemples qui restent.
Implémentation
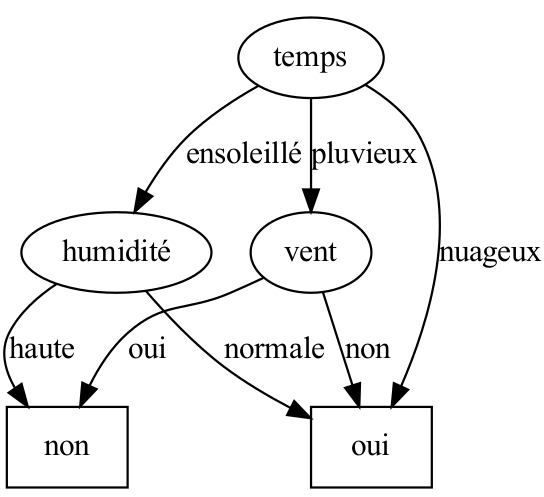
Vous allez donc implémenter en Python l'algorithme ID3, pour dans un premier temps travailler sur l'exemple dont les données ont été présentées ci-dessus, et qui doit alors mener à l'arbre de décision suivant :

...qui montre une conclusion pas évidente du tout au premier abord : la température n'intervient pas du tout dans la décision finale ! 😳
Structure de données utilisée
Les données d'apprentissage sont dans ce fichier.
Télécharger ce fichier, qui contient un code à compléter.
Pour stocker les exemples d'entraînement qui serviront à créer l'arbre, les données extraites du fichier seront placées dans un tableau de dictionnaires, grâce au module
csv de Python.
Chaque exemple correspondra à un dictionnaire dans ce tableau, dont les clés seront les titres des colonnes dans le fichier de données ( première ligne ), et les valeurs correspondantes, les valeurs dans les colonnes :
[{'temps': 'ensoleillé', 'température': 'chaude', 'humidité': 'haute', 'vent': 'non', 'jouer': 'non'},
{'temps': 'ensoleillé', 'température': 'chaude', 'humidité': 'haute', 'vent': 'oui', 'jouer': 'non'},
{'temps': 'nuageux', 'température': 'chaude', 'humidité': 'haute', 'vent': 'non', 'jouer': 'oui'},
{'temps': 'pluvieux', 'température': 'douce', 'humidité': 'haute', 'vent': 'non', 'jouer': 'oui'},
...]
L'arbre de décision et son algorithme de création seront implémentés en POO.
- Compléter le constructeur de la classe
ArbreDecisionci-dessous afin d'affecter les valeurs aux attributs de cette classe. - Tester ce constructeur en instanciant un objet, et en affichant les valeurs de ses attributs.
import csv
class ArbreDecision:
def __init__(self, data: list[dict[str]]):
self.exemples = data
self.titres = ... # titres des colonnes de données = clefs de chaque dictionnaire dans le tableau d'exemples
self.etiquette = ... # la décision à prendre = le dernier titre
self.attributs = ... # tableau des attributs = les titres, sauf l'étiquette
# Extraction des données
data = []
with open("data_tennis.csv", 'r') as file:
reader = csv.DictReader(file)
for row in reader:
data.append(row) # tableau des dictionnaires de données
Méthodes auxiliaires
Avant d'implémenter l'algorithme ID3 proprement dit, vous aurez besoin de coder quelques fonctions utilitaires :
Liste des valeurs possibles pour une colonne de donnée
Écrire une méthode valeurs_possibles de la classe ArbreDecision, qui :
- prend comme paramètre un ensemble d'exemples et un titre de colonne ( un attribut ou l'étiquette ),
- renvoie le tableau des différentes valeurs possibles que peuvent prendre les valeurs de la colonne dans les exemples.
Par exemple,
doit renvoyer :valeurs_possibles(exemples, "temps")
.["ensoleillé", "nuageux", "pluvieux"]
Tester bien entendu cette méthode !
classe ArbreDecision
...
def valeurs_possibles(self, exemples: list[dict[str]], titre: str)->list[str]:
"""
Détermine les valeurs possibles dans une colonne de titre donné dans un ensemble d'exemples.
"""
pass
Sous-ensemble de données répondant à un critère
Écrire une méthode sous_ensemble de la classe ArbreDecision, qui :
- prend comme paramètre un ensemble d'exemples, un attribut et une valeur ( possible pour cet attribut, bien entendu )
- renvoie le tableau des exemples pour lesquels l'attribut a cette valeur.
( Un peu comme un : SELECT * FROM exemples WHERE attribut = valeur 😎...)
Tester bien entendu cette méthode !
classe ArbreDecision
...
def sous_ensemble(self, exemples: list[dict[str]], attribut: str, valeur: str)->list[dict[str]]:
"""
Renvoie un sous-ensemble d'exemples pour lesquels un attribut donné a une certaine valeur.
"""
pass
Classe la plus fréquente dans un ensemble
Écrire une méthode classe_la_plus_frequente de la classe ArbreDecision, qui :
- prend comme paramètre un ensemble d'exemples
- renvoie le nom de la classe la plus fréquente, c'est à dire la valeur de l'étiquette qui apparaît le plus souvent dans l'ensemble d'exemple.
Par exemple,
( oùclasse_la_plus_frequente(data)dataest l'ensemble de tous les exemples d'entraînement ) doit renvoyer :
( il y a 9 décisions 'oui' et seulement 5 'non' dans les données ).oui
Tester bien entendu cette méthode !
classe ArbreDecision
...
def classe_la_plus_frequente(self, exemples: list[dict[str]]-str:
"""
Renvoi le nom de la classe la plus fréquente dans un ensemble d'exemples.
"""
pass
Meilleur attribut
Attention, le cœur de l'algorithme !!
On vous fournit deux fonctions :
entropie, qui calcule l'entropie d'un ensemble d'exemplesgain_info, qui calcule le gain d'information pour un attribut donné
Ne vous préoccupez pas du code de ces deux méthodes.
Écrire une méthode meilleur_attribut de la classe ArbreDecision, qui utilise la méthode gain_info, et qui :
- prend comme paramètre un ensemble d'exemples et un tableau d'attributs à tester
- renvoie l'attribut apportant le gain d'information le plus grand.
Testez cette méthode; par exemple, avec le tableau complet des exemples, la méthode doit renvoyer "temps" ( c'est l'attribut qui apporte au début le plus d'information ).
classe ArbreDecision
...
def entropie(self, ensemble: list[dict[str]])->float:
"""
Calcul et renvoie l'entropie de Shannon d'un ensemble
"""
# code non étudié dans ce TP
def gain_info(self, ensemble:list[dict[str]], attribut: str)->float:
"""
Calcule et renvoie le gain d'information apporté par un attribut donné pour un ensemble donné.
"""
# code non étudié dans ce TP
def meilleur_attribut(self, ensemble: list[dict[str]], liste_attributs)->str:
"""
Dans une liste d'attributs, recherche l'attribut apportant le meilleur gain d'information pour un ensemble d'exemples.
"""
pass
Algorithme ID3
Vous en arrivez à l'implémentation de l'algorithme; mais auparavant, il faut discuter de la structure de données utilisée pour représenter les nœuds de l'arbre.
La classe Noeud
On utilisera une seule classe pour représenter les nœuds internes de l'arbre ou les feuilles :
class Noeud:
def __init__(self, valeur: str, enfants = None):
self.valeur = valeur
self.enfants = enfants # de type dictionnaire Python
- une feuille n'a qu'une valeur.
- un nœud a une valeur ( = l'attribut correspondant à ce nœud ), et ses enfants sont stockés dans un dictionnaire dont :
- les clés sont les valeurs possibles de l'attribut
- les valeurs, les nœuds enfants correspondants à ces valeurs
Ce dictionnaire sera rempli après l'instanciation du nœud ( à l'instanciation, ce sera donc un dictionnaire vide ).
On stocke donc dans les nœuds internes aussi bien l'attribut testé que les différentes valeurs que peut prendre cet attribut :
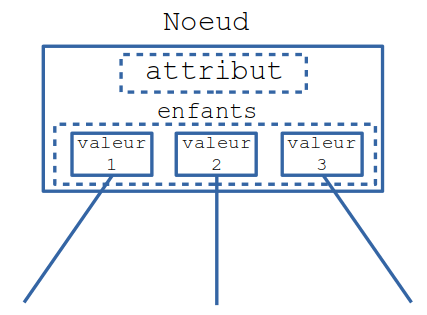
Attention alors dans l'algorithme à la manière d'instancier un nœud ou une feuille !
L'algorithme
Il ne vous reste plus qu'à implémenter l'algorithme présenté ci-dessus.
Vous pouvez le faire "from scratch", ou alors compléter le code ci-dessous :
class ArbreDecision:
...
def creer_arbre(self, exemples: list[dict[str]], liste_attributs: list[str])->Noeud:
# si tous les exemples appartiennent à la même classe
# on a trouvé un ensemble homogène, on créé alors une feuille.
if ... :
# on détermine la classe (unique) à laquelle appartiennent alors les exemples,
classe = ...
# et on crée une feuille avec comme valeur la classe en question
return ...
# s'il ne reste plus d'attribut à tester,
# on crée une feuille correspondant à la classe la plus fréquente
# dans l'ensemble d'exemples restant.
if len(liste_attributs) == 0:
classe = ...
return ...
# détermination du meilleur attribut, et création du nœud associé
attribut_optimal = ...
# si il n'y a pas d'attribut optimal ( ils se valent tous ! ),
# alors on crée une feuille ayant comme valeur la classe la plus fréquente
if attribut_optimal == '':
classe = ...
return ...
# sinon, on crée le noeud associé à cet attribut optimal,
# et on supprime celui-ci de la liste des attributs à étudier par la suite
noeud = ...
liste_attributs.remove(attribut_optimal)
# création des nouveaux nœuds correspondant au partage de l'ensemble d'exemples actuel :
for valeur in ... : # pour chaque valeur possible de l'attribut optimal,
s = ... # on crée le sous-ensemble d'exemples correspondant à la valeur de cet attribut,
noeud.enfants[valeur] = ... # et on crée récursivement les nœuds enfants
return noeud
Une fois ceci fait, créer alors l'arbre, en écrivant une instruction à la fin du constructeur de la classe ( l’instanciation d'un objet déclenchera donc immédiatement la création de l'arbre ), et en affectant l'arbre créé à un nouvel attribut de la classe .
Affichage de l'arbre
Tout fonctionne sans erreur ? Ce n'est déjà pas mal ! Mais il serait bien entendu utile de visualiser l'arbre de décision créé...
Affichage textuel
Écrire une fonction ( récursive ! ) qui permet d'afficher l'arbre sous la forme de ses différents "niveaux" :
temps ensoleillé
humidité haute
non
humidité normale
oui
temps nuageux
oui
temps pluvieux
vent non
oui
vent oui
non
Une suite de tabulation(s) ( caractère '\t' ) permet "d'indenter" chaque "niveau" de l'arbre : 0 tabulations pour le premier, une seule pour le deuxième, etc...
A chaque niveau de nœuds internes, on affiche sur la même ligne le nom ET la valeur de l'attribut; pour une feuille, on n'affiche que le nom de la classe.
class ArbreDecision:
...
def affiche(self, noeud, niveau = 0):
"""
Affiche l'arbre sous forme textuelle.
"""
pass
Affichage avec le module Python graphviz
Le module graphviz permet, comme son nom l'indique, de visualiser des graphes, mais un arbre étant un type particulier de graphes, on peut s'en servir ici.
Vous trouverez dans le code fourni un ensemble de deux méthodes ( une publique, celle à appeler, et l'autre privée ), qui permettent d'afficher l'arbre avec le module graphviz, si celui-ci est installé sur votre machine ( sinon il est disponible dans les éditeurs du site ).
On doit obtenir :
Classification d'un exemple non étiqueté
Il est maintenant temps d'exploiter l'arbre de décision pour classer des exemples non étiquetés.
Par exemple :
{'temps': 'ensoleillé', 'température': 'douce', 'humidité': 'normale', 'vent': 'oui'}
{'temps': 'nuageux', 'température': 'chaude', 'humidité': 'basse', 'vent': 'oui'}
...
...ou tout exemple qui n'apparaît pas dans les données d'apprentissage !
Écrire une méthode etiqueter de la classe ArbreDecision, qui :
- prend comme paramètre un dictionnaire {attributs: valeurs} pour un exemple non étiqueté
- renvoie la valeur de l'étiquette de cet exemple ( = le nom de la classe à laquelle il appartient ).
Bien entendu, vérifier que l'étiquetage est correct !
{'temps': 'ensoleillé', 'température': 'chaude', 'humidité': 'normale', 'vent': 'oui'}
{'temps': 'pluvieux', 'température': 'fraîche', 'humidité': 'haute', 'vent': 'non'}
...
class ArbreDecision:
...
def etiqueter(self, exemple:dict[str])->str:
"""
Renvoie la classe à laquelle appartient l'exemple.
"""
pass
Et pour terminer...
Servez vous des fichiers de données ( = datasets ) suivants pour répondre aux questions posées :
Ces données sont traitées de manière statistique par l'algorithme, il ne faut donc pas prendre les résultats obtenus au pied de la lettre.
De plus, certaines de ces données ont été volontairement rendues erronées...
- Prix d'appartements en fonction de différents critères : quel est le prix d'un appartement de 30m², au 3ème étage d'un immeuble qui en compte 7, avec 5 chambres, 1 salle de bain, 1 balcon, un chauffage électrique et 2 places de parking ?
- Accords de prêts en fonction des caractéristiques du demandeur : un étudiant de 20 ans qui vit chez ses parents, sans enfant ni conjoint, dont le revenu est de 0€ par mois, et qui n'a encore aucun crédit en cours, pourra-t-il obtenir un prêt ? Un retraité de 60 ans, dont le revenu est de 50000€, ayant 3 enfants, dont l'épouse ne travaille pas, propriétaire de sa maison, avec un crédit en cours de 1000€, obtiendra-t-il son prêt ? ( oh surprise dans les deux cas )
- Diagnostic médical ( en anglais ) : à vous de faire votre diagnostic ! ( attention, l'arbre est long à créer ).
- Facteurs influençant le niveau des étudiants à l'université : quel est le critère qui influe le plus ?
En conclusion
Avantages de l'algorithme ID3
- simple et (relativement) facile à comprendre
- ne demande pas une très grande quantité de données d'entraînement
Inconvénients
- il présente le biais de trop privilégier certains attributs au détriment d'autres
- il peut ne pas être très efficace avec des données présentant un grand nombre d'attributs; si ceux-ci peuvent à leur tour prendre de nombreuses valeurs différentes, alors l'arbre résultant contiendra un très grand nombre de nœuds.
Des améliorations ont été apportées, comme le successeurs de ID3, l'algorithme C4.5 par exemple.
Applications de ID3
- Détection de fraudes
- Systèmes de recommandation : Amazon utilise ID3 pour recommander des produits à ses clients, Netflix pour recommander des films, Spotify des musiques, etc...
- diagnostic médical
- ...
Correction
Une correction possible pour ce TP.