TP : Multitâche et ordonnancement
Un système d'exploitation est dit multitâche lorsqu'il est capable de simuler l'exécution simultanée de plusieurs processus indépendamment du nombre de cœurs disponibles dans le microprocesseur.
Pour mettre en œuvre le multitâche, deux approches sont possibles :
- Le multitâche coopératif ( = non préemptif ) qui consiste à laisser les processus "décider" du moment où ils doivent rendre la main aux autres.
Dans ce cas, chaque processus, une fois élu, termine complètement son exécution avant de "passer la main" aux processus suivants; même si ces algorithmes peuvent être efficace en terme de répartition "équitable" du temps processeur entre les différentes processus, ils ont l'inconvénient que si un processus "bloque", le système tout entier peut se retrouver bloqué.
C'est ce type de multitâche que l'on retrouve dans les (très) anciennes versions de Windows 3.11 (1993) ou Mac OS 9 (1999). - Le multitâche préemptif qui consiste à octroyer un certain temps d'exécution au processus avant de reprendre la main de force en sauvegardant l'état du processus, au moyen d'une
interruption programmable.
Ce type de multitâche se retrouve dans les systèmes d'exploitation Unix (1969) ( dont Linux est issu ) et Windows NT (1993) mais aussi dans les systèmes plus grand-public comme AmigaOS (1985), Windows 95 (1995) et Mac OS X (2001).
Un processus ne peut donc pas bloquer le reste du système; en accordant quelques millisecondes de temps d'exécution à chaque processus, un système d'exploitation multitâche préemptif comme Linux, doit cependant effectuer de nombreuses commutations de contexte (sauvegardes et restauration des registres du processeur, changement de l'espace d'adressage,…) avec un impact parfois non négligeable sur les performances du système.
Il convient alors de gérer "au mieux" l'ordre et le temps d'exécution des processus en prenant en compte leurs priorités et l'accès aux ressources du système, tout en maintenant une certaine "équité" entre les processus. On appelle ce pilotage l'ordonnancement.
Le but de ce TP est de comprendre et de simuler en Python quelques algorithmes d'ordonnancement de processus parmi les nombreux qui existent.
Situation étudiée
Nous considérerons la situation simplifiée de quatre processus P1, P2, P3 et P4 ( de même priorité ), dont la date de début d’exécution, ainsi que la durée de cette exécution, sont données dans la figure ci-dessous par l'échelle de temps ( 1 unité de temps = 1 "tick" d'horloge = 1 carré ) :
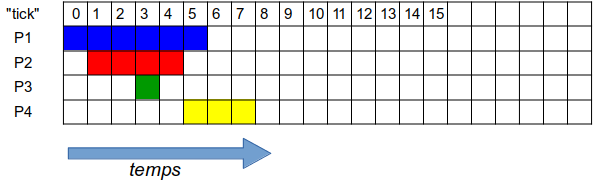
Mais un seul processus peut s'exécuter à la fois ( système mono-cœur ) : les 4 processus ne peuvent donc pas s’exécuter en parallèle comme la figure peut le laisser croire; il faudra donc bien plus de 8 "ticks" d'horloge pour terminer l'exécution complète des 4 processus...
Un algorithme d'ordonnancement devra donc forcément gérer une "file d'attente" dans laquelle les processus "séjourneront" plus ou moins longtemps..
Cette file est appelé file d'exécution ( = running queue ).
Modélisation des processus
Vous trouverez ci-dessous le code d'une classe Processus, qui modélise un processus.
Utiliser cette classe pour créer un tableau Python contenant 4 instances de la classe Processus modélisant les 4 processus de la situation étudiée :
Quelques exemples d'algorithmes d’ordonnancement
Ressources fournies
Dans l'éditeur ci-dessous, on a défini une classe Ordonnanceur, qui contient les méthodes communes nécessaires à tous les
algorithmes que vous allez étudier dans ce TP.
Le code de cette classe n'est pas destiné à être modifié; exécutez le simplement afin que la classe soit disponible dans les autres éditeurs de la page.
- vous pouvez étudier la documentation de cette classe afin de connaître les méthodes et les attributs que vous pouvez utiliser.
- dans la suite du travail, vous écrirez des classes qui héritent de la classe
Ordonnanceur( rappel : pas au programme, mais bien pratique !... ), c'est à dire des classes qui disposent des mêmes méthodes que la classeOrdonnanceur, mais auxquelles on peut en rajouter d'autres plus spécifiques. - notamment, vous écrirez une méthode
insererqui devra gérer l'insertion d'un processus dans la file d’exécution de l’ordonnanceur en fonction de l'algorithme que celui-ci utilise.
Cette file d’exécution sera modélisée par un tableau Python ( même si ce n'est pas l'implémentation la plus efficace 😒...). - la classe
Ordonnanceurpropose une méthode d'affichage pour visualiser la file d'exécution.
Fonctionnement de l'ordonnanceur
La méthode tick de la classe Ordonnanceur simule le déroulement de l’ordonnancement lors d'un "tick" d'horloge :
- si un nouveau processus se présente, on l'insère dans la file d’exécution;
- on exécute ensuite le processus élu;
- si ce dernier est terminé, on le sort de la file d’exécution;
La méthode ordonnancement permet de dérouler l'ordonnancement tant qu'il reste des processus à exécuter.
Algorithmes non-préemptifs
Algorithme FIFO
Ça, ça doit vous parler...
Avec cet algorithme, chaque processus est inséré en queue de file d’exécution en fonction de sa date d'arrivée, et c'est le premier entré dans la file qui est complètement exécuté, sans interruption, avant de laisser l’exécution au suivant dans la file.
La file d’exécution complète des 4 processus est dans ce cas :
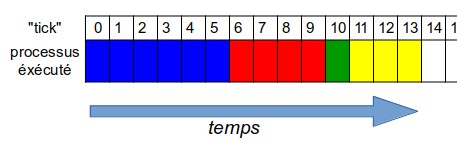
Cet algorithme ne tient donc absolument pas compte de la durée relative de chaque processus : un "gros" processus monopolise donc le temps machine tant qu'il n'est pas terminé.
Implémentation
- Écrire le code d'une nouvelle classe
FIFO, qui hérite de la classeOrdonnanceur, et qui implémente une méthodeinsérer, qui prend comme paramètre un processus, et qui l'insère dans la file d’exécution de l'ordonnanceur en suivant l’algorithme FIFO. - instancier un objet de type FIFO en lui passant le tableau des 4 processus étudiés.
- lancer la simulation de l'ordonnancement, et afficher son résultat.
Performances
Pour comparer les "performances" des différents algorithmes d'ordonnancement, on peut calculer deux "métriques" :
- le temps moyen de séjour d'un processus, qui est la moyenne des temps de séjour de chaque processus, c'est à dire la durée entre la date d'entrée d'un processus dans la file d’exécution, et sa date de sortie; par exemple, le processus P2 ( en rouge ) entre dans la file au "tick" 1, et en ressort au "tick" 10 : son temps de séjour est donc de 10 - 1 = 9 "ticks".
- le temps d'attente moyen d'un processus, qui est la moyenne des temps d’attente de chaque processus, c'est à dire la durée entre la date d'entrée d'un processus dans la file d’exécution, et la date effective de son début d'exécution; par exemple, P2 entre dans la file au "tick" 1, mais n'est exécuté qu'au "tick" 6 : son temps d'attente est donc 6 - 1 = 5 "ticks".
Bien entendu, plus ces deux "métriques" sont petites, plus efficace et "équitable" est l'algorithme ( on se doute que ce ne sera pas le cas ici 😅 ... )
Calculer le temps de séjour de chaque processus, puis le temps de séjour moyen d'un processus; faire de même pour le temps d'attente :
Algorithme du plus court d'abord ( SJF = Shortest Job First )
Une autre méthode est de prioriser les processus ayant le temps d'exécution le plus court : lorsqu'un processus se présente dans la file d’exécution, il n'interrompt pas l'exécution du processus
en cours d'exécution ( = processus élu ), mais il est placé dans la file d’exécution devant les processus déjà présents mais ayant une durée d'exécution plus longue; dans la suite des opérations d'ordonnancement, il sera
donc élu avant ces derniers.
Les processus dans la file d'exécution se trouvent donc "triés" par ordre de durée d’exécution croissante.
Il s'agit donc d'un algorithme glouton...
- appliquer cet algorithme à l'ordonnancement des 4 processus de la situation étudiée.
- Écrire le code d'une nouvelle classe
SJF, qui hérite de la classeOrdonnanceur, et qui implémente une méthodeinsérer, qui prend comme paramètre un processus, et qui l'insère dans la file d’exécution de l'ordonnanceur en suivant l’algorithme SJF. Pour cette insertion, on pourra suivre le principe suivant : insérer d'abord le processus en queue de file, puis lui trouver sa place en utilisant l’algorithme utilisé lors du tri par insertion.
Performances
Calculer le temps de séjour de chaque processus, puis le temps de séjour moyen d'un processus; faire de même pour le temps d'attente :
Algorithmes préemptifs
Dans ce type d'algorithme, l'exécution du processus élu peut être interrompue, pour laisser la place à l’exécution d'un autre processus; l'exécution du premier reprendra alors plus tard en fonction de l'algorithme utilisé.
Algorithme du plus court temps restant en premier ( SRTF = Shortest Remaining Time First )
Il s'agit de la version préemptive de l'algorithme SJF précédent : lorsqu'un processus se présente dans la file d’exécution, il peut interrompre l'exécution du processus élu, dans le cas où sa durée d’exécution est plus petite que la durée restante d’exécution de ce dernier : le nouveau processus est donc placé en tête de file, il s'exécute, puis "l'ancien" processus élu reprend son exécution ( à moins qu'un processus plus court se présente à nouveau !...).
- appliquer cet algorithme à l'ordonnancement des 4 processus de la situation étudiée.
- Écrire le code d'une nouvelle classe
SRTF, qui hérite de la classeOrdonnanceur, et qui implémente une méthodeinsérer, qui prend comme paramètre un processus, et qui l'insère dans la file d’exécution de l'ordonnanceur en suivant l’algorithme SRTF. ( Remarque : une très légère adaptation du code de l'algorithme SJF suffit 😎 ... )
Performances
Calculer le temps de séjour de chaque processus, puis le temps de séjour moyen d'un processus; faire de même pour le temps d'attente :
Algorithme du tourniquet ( RR = Round Robin )
L'approche de cet algorithme est différente : les processus sont insérés dans la file d’exécution en fonction de leur date d'arrivée, sans tenir compte de leur durée d’exécution.
A chaque processus est accordée une durée fixe d’exécution, appelée quantum de temps ( exprimé en "ticks" d'horloge ); le processus élu s’exécute pendant un quantum de temps, à l'issue duquel il est replacé en queue de file pour laisser la place au processus suivant, même si son exécution n'était pas terminée.
C'est donc une répartition complètement équitable du temps machine entre les processus.
- appliquer cet algorithme à l'ordonnancement des 4 processus de la situation étudiée avec un quantum de temps égal à 2.
- Écrire le code d'une nouvelle classe
RR, qui hérite de la classeOrdonnanceur, et qui implémente :- une nouvelle méthode
tick( à compléter ) qui tiendra compte des spécificités de cet algorithme; - une méthode
insérer, qui prend comme paramètre un processus, et qui l'insère dans la file d’exécution de l'ordonnanceur en suivant l’algorithme RR.
- une nouvelle méthode
Performances
Calculer le temps de séjour de chaque processus, puis le temps de séjour moyen d'un processus; faire de même pour le temps d'attente :
Conclusion
Chaque algorithme a ses avantages et ses inconvénients, et est vraiment adapté à une situation particulière : par exemple, SJF/SRTF sont mal adaptés si on ne sait pas déterminer avec précision la durée d'exécution d'un processus ( on est d'ailleurs en pratique obligé de calculer une "moyenne" pour cette durée, en fonction de celles des processus déjà exécutés ).
Ces algorithmes ne tiennent de plus pas compte de la priorité des processus : les logiciels gérant des interfaces graphiques devront par exemple prioriser les processus gérant les interactions avec l'utilisateur pour plus de réactivité de l'interface.
Un "vrai" algorithme d'ordonnancement utilise souvent des structures de données plus complexes qu'une simple file afin de gérer toutes ces contraintes.
Correction
Une correction de ce TP peut être trouvée ici.