Python et les processus
Divers modules permettent de manipuler les processus à l'aide de Python :
- le module
osqui permet, entre autres, de déterminer les caractéristiques de tel ou tel processus et de créer de nouveaux processus-fils - enfin, le module
multiprocessing, qui permet de lancer plusieurs "vrais" processus indépendants
Création de processus-fils
Le module os propose, entre autres, les fonctions qui font des appels systèmes au noyau du système d'exploitation pour qu'il crée de nouveaux processus.
Le module s'importe en début de script :
import os
Nous utiliserons les fonctions suivantes de ce module :
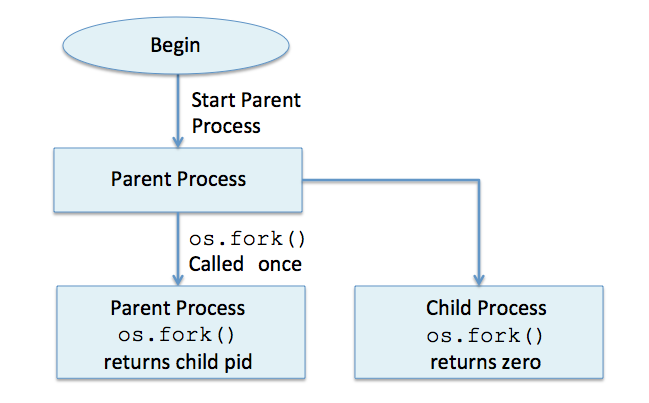
os.getpid(): renvoie le PID du script en cours ( en fait, le PID du processus correspondant à l'interpréteur Python )os.getppid(): renvoie le PPID du processus, c'est à dire le PID de son processus-pèreos.fork(): crée un processus-fils à partir du processus en cours.
Comme cette fonction crée une copie du processus appelant, chacun des deux processus exécutera alors le même code qui suit l'appel defork().
La fonction n'est appelée qu'une seule fois, mais renvoie une valeur différente dans chaque copie :- 0 dans le processus-fils
- le PID du processus-fils dans le processus-père
- une valeur négative si la création du processus-fils a échoué
A cause du modèle de système d'exploitation utilisé, la fonction fork() n'existe pas sous Windows.
- écrire une fonction
infos()qui affiche le PID et le PPID du processus en cours :PID = 3545 PPID = 3542 - écrire une fonction
nv_fils()qui :- crée un processus-fils à partir du processus principal
- affiche le PID et le PPID du processus en cours d'exécution en distinguant les processus père et fils :
Je suis 6135 le fils de 6124 Je suis 6124 le père de 6135
- Lancer plusieurs fois de suite le script précédent. Que constate-t-on ? Comment expliquer cela ?
- pour encore mieux visualiser ceci, écrire une fonction
deux_fils()pour créer deux processus-fils du même père.
Attention, ce n'est pas évident : où dans le script doit-on placer le deuxième appel à la fonctionfork()?
Les difficultés de la gestion des processus
Lancement de processus
Vous allez maintenant utiliser le module multiprocessingde Python, qui permet de lancer plus simplement des processus.
On importe les fonctions de ce module au début du script :
from multiprocessing import Process
Pour créer un processus, on l'associe à une fonction qu'il doit exécuter, en indiquant les éventuels arguments à lui passer :
p = Process(target = nom_de_la_fonction, args = [argument1, argument2, ...])
On lance alors le processus :
p.start()
Enfin, pour attendre que le processus ait terminé son exécution :
p.join()
On peut ainsi définir plusieurs processus puis les lancer successivement.
Deux processus concurrents
- écrire une fonction
alpha()qui affichera :- le PID du processus qui l’exécute, valeur passée en argument à la fonction
- les lettres de l'alphabet dans l'ordre
Je suis le processus 4595 et j'affiche : C Je suis le processus 4564 et j'affiche : C ......Pour éviter d'éventuels problèmes d'affichage dus à la trop grande rapidité d'alternance des processus, vous pouvez au besoin rajouter un petit délai après l'affichage à l'aide de la fonction
sleep()que vous aurez importée au début du script à partir du moduletime.
Par exemple :sleep(0.02)( à adapter en fonction de la machine ). - créer 2 processus qui exécuteront en concurrence la fonction
alpha().
Attention à les démarrer tous les deux successivement avant d'attendre la fin de leur exécution. - Observer et interpréter l'affichage obtenu.
Encore plus de processus
Qu'en est-il dans une situation plus proche de la réalité, où un grand nombre de processus s’exécutent en "parallèle" ?
- écrire une fonction
nombrequi affichera :- le PID du processus qui l’exécute,
- une valeur entière croissante de 1 à 10
Je suis le processus 3648 et j'affiche : 5 Je suis le processus 3789 et j'affiche : 4 ...... - créer 10 processus qui exécuteront en concurrence la fonction
nombre().
On aura intérêt à :- à créer et lancer les processus dans une boucle, le compteur de boucle indiquant le numéro du processus lancé.
- stocker les processus dans une liste pour un accès plus facile
- utiliser une autre boucle pour attendre la fin de l'exécution de chaque processus ( si l'on faisait cela dans la même boucle que celle de création des processus, on devrait attendre la fin de l’exécution de chacun avant de lancer le suivant : aucun intérêt ! ).
- lancer le script plusieurs fois de suite; interpréter l'affichage observé.
Le problème de l'accès à des ressources communes
Dans l'exemple précédent, les processus s'exécutaient indépendamment les uns des autres, mais qu'en est-il si ils sont prévus pour traiter une même ressource ?
Normalement, les processus disposent de leur propre espace mémoire; mais il est des situations où il est nécessaire que les processus puissent échanger des données entre eux, ou alors qu'ils aient besoin de travailler sur les mêmes données.
Nous allons voir ainsi le cas de plusieurs processus destinés à modifier la valeur d'une variable commune.
Puisqu'ils disposent de leur propre espace mémoire, les processus ne peuvent pas simplement manipuler les mêmes variables; pour qu'ils puissent partager des données, il faut le faire en
utilisant des objets spéciaux appelés Value ( valeur unique ) ou Array ( tableau ).
On les importe depuis le module :
from multiprocessing import Process, Value, Array
Pour créer un objet de type Value ou Array :
num = Value('i', 3) # pour une valeur entière
tab = Array('d', [1.0, 2.5, 6.48]) # pour des valeurs flottantes
Ces objets peuvent être ensuite être passés comme arguments à des fonctions qui pourront les manipuler.
Notamment, pour modifier un objet de type Value, il faut en fait modifier son attribut value :
num.value = 3.154
- écrire une fonction
incr()qui incrémentera jusqu'à 500000 ( oui, on veut des processus qui durent un peu de temps...) un compteurcompteurqui sera partagé entre les processus. - créer 10 processus qui exécuteront en concurrence la fonction
incr(compteur). - Quelle valeur aura
compteurà la fin de l'exécution des 10 processus ? - lancer le script plusieurs fois de suite; interpréter l'affichage observé.
La solution : les verrous
Pour éviter le problème précédent, il nous faut garantir l’accès exclusif d'un seul processus à la fois à la donnée compteur entre sa lecture et son écriture.
Pour cela on peut utiliser un verrou : c'est un objet qu’un processus peut essayer "d’acquérir"; si il est le premier à le faire ( c'est à dire si le
verrou est "libre"), il acquiert le verrou, et il a alors le "droit" d'exécuter son code.
Si un second processus essaye d’acquérir un verrou déjà pris, il sera bloqué jusqu’à ce que le verrou soit libéré.
On garantit ainsi qu'un seul processus à la fois peut accéder à une ressource donnée. La portion de code qu'il exécute alors s'appelle section critique car c'est elle qui ne doit pas être interrompue par un autre processus.
Bien entendu, à la fin de son exécution, le processus qui a pris le verrou doit alors le "libérer"...nous verrons ce qu'il se passe si ce n'est pas le cas !
En Python, un verrou ( Lock ) s'importe à partir du module multiprocessing :
from multiprocessing import Process, Value, Lock
On le crée comme n'importe quel objet en appelant son constructeur ( sans argument ) dans le programme principal et en l'affectant à une variable.
v = Lock()
Pour qu'un processus acquiert ou libère un verrou, on utilise alors les méthodes acquire() et release() :
v.acquire()
......
section critique
......
v.release()
- dans le script précédent, identifier la section critique de la fonction exécutée par les processus.
- utiliser alors le mécanisme de verrou décrit ci-dessus pour "protéger" cette section critique.
- lancer plusieurs fois de suite le script pour constater la disparition du problème précédent.
Ah oui, forcément, le temps d'exécution est beaucoup plus grand : on perd le bénéfice du "parallélisme", puisque chaque processus doit attendre qu'un autre ait fini de s'exécuter avant de pouvoir le faire...
Mais dans une situation réelle, on n'aurait pas un traitement aussi simple des données, et l'exécution de plusieurs processus "simultanés", protégée par ce système de verrou, serait quand même bénéfique au temps d'exécution...
Le problème de l'interblocage
Et donc, que se passe-t-il si un processus ne libère pas un verrou comme il est censé honnêtement le faire ? 😇
Le problème se pose quand plusieurs processus doivent accéder à plusieurs ressources communes.
Considérons la situation suivante :
A un carrefour de deux routes se présentent des véhicules qui veulent continuer tout droit; les règles du code de la route impose que c'est le véhicule venant de droite qui a la priorité.
Si les voitures n'arrivent pas au même moment au carrefour, il n'y a pas de problème; mais si elles s'y présentent toutes simultanément, aucune ne se retrouve alors plus prioritaire qu'une autre : elles se bloquent mutuellement le passage. On dit qu'il y a interblocage entre les véhicules.
De manière analogue, dans un ordinateur où s'exécutent plusieurs processus accédant aux mêmes ressources :
- chaque processus correspond à une voiture; la ressource utilisée par le processus est le passage tout droit
- un processus se présente au carrefour : le processus acquiert alors un verrou sur son passage tout droit.
- cependant, il a aussi priorité sur le processus venant à sa gauche : il acquiert donc également un verrou qui "bloque" le processus venant à sa gauche.
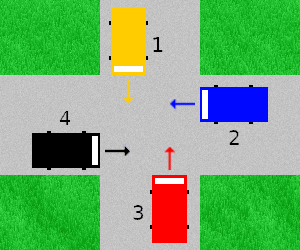
Par exemple, sur l'exemple ci-contre, quand le processus 1 arrive au carrefour :
- il acquiert un verrou sur le passage 1
- il acquiert également un verrou sur le passage 2
De même, quand le processus 3 arrive au carrefour :
- il acquiert un verrou sur le passage 3
- il acquiert également un verrou sur le passage 4
Là aussi, tant que les processus s’exécutent sagement les uns après les autres, il n'y a pas de problème...mais on sait que ce n'est pas le cas !
L'ordonnancement non prévisible des processus par le système d'exploitation fait que le processus 2 peut très bien déjà avoir acquis le verrou sur le passage 2, et bloque
donc également le passage 3, qui lui-même bloque peut-être le passage de 4, qui lui-même bloque 1...
Selon le moment où chaque processus s'exécute, on arrive donc aussi à une situation d'interblocage, chaque processus attendant une ressource qui ne peut être libérée que par un autre processus...
Le script ci-dessous illustre cette situation :
from multiprocessing import Process, Lock
from random import random
from time import sleep
v1 = Lock()
v2 = Lock()
v3 = Lock()
v4 = Lock()
def passer1():
while True:
v2.acquire()
v1.acquire()
print('Passage voiture Route 1')
sleep(0.02)
v1.release()
v2.release()
def passer2():
while True:
v3.acquire()
v2.acquire()
print('Passage voiture Route 2')
sleep(0.02)
v2.release()
v3.release()
def passer3():
while True:
v4.acquire()
v3.acquire()
print('Passage voiture Route 3')
sleep(0.02)
v3.release()
v4.release()
def passer4():
while True:
v1.acquire()
v4.acquire()
print('Passage voiture Route 4')
sleep(0.02)
v4.release()
v1.release()
p1 = Process(target = passer1, args = [])
p2 = Process(target = passer2, args = [])
p3 = Process(target = passer3, args = [])
p4 = Process(target = passer4, args = [])
p1.start()
p2.start()
p3.start()
p4.start()
p1.join()
p2.join()
p3.join()
p4.join()
- lancer plusieurs fois de suite ce script. Que constate-t-on ?
- pour "tuer" le script, utiliser l'icône
 au dessus de l'interpréteur dans Pyzo ( ou alors utiliser les commandes du Terminal vues au
chapitre précédent ! )
au dessus de l'interpréteur dans Pyzo ( ou alors utiliser les commandes du Terminal vues au
chapitre précédent ! )
Une situation d'interblocage se produit donc quand chaque processus attend une ressource qui ne peut être libérée que par un autre processus.
Les problèmes d'interblocage peuvent se produire de manière imprévisible dans un système, et sont toujours très délicats à résoudre...
QCM d'entraînement ( d'après Bac )
Avec une ligne de commande dans un terminal sous Linux, on obtient l'affichage suivant :
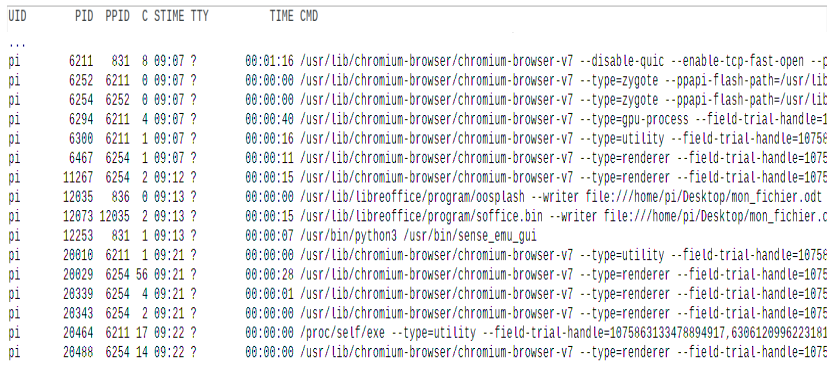
La documentation Linux donne la signification de quelques uns des champs :
- UID : identifiant utilisateur effectif ;
- C : partie entière du pourcentage d'utilisation du processeur par rapport au temps de vie des processus ;
- STIME : l'heure de lancement du processus ;
- TTY : terminal de contrôle
- TIME : temps d'exécution
- CMD : nom de la commande du processus