Le type abstrait Dictionnaire
Le type abstrait dictionnaire (appelé aussi tableau associatif) et une structure de données dont le nom est très évocateur. Comme dans un dictionnaire linguistique,
une clef (le mot) est associé à une valeur (la définition).
Par contre, contrairement à un dictionnaire linguistique, la structure de données n'est pas du tout ordonnée, nous verrons plus tard que le mode de recherche dans les dictionnaires
est néanmoins très optimisé. Voici quelques exemples de données adaptées à cette structure :

- Un agenda téléphonique -> clefs : noms ; valeurs : numéros de téléphone
- Fichier de carte d'identité -> clefs : numéros de carte ; valeurs : noms et prénoms des titulaires
Un dictionnaire peut aussi regrouper plusieurs informations de natures différentes :
- prénom : Léo
- nom : Gruoleb
- classe : 111
- spécialité 1 : NSI
- spécialité 2 : NSI
- option fac : Latin
- date de naissance : 03/12/2004
Ici prénom, nom, classe, spécialité 1, spécialité 2, option fac et date de naissance sont les clefs.
Et Léo, Gruoleb, 111, NSI, Latin, 03/12/2004 sont les valeurs.
Utiliser les dictionnaires python
Comme vous le savez, le type dictionnaire existe déjà en python ( type dict ), vous l'avez sûrement déjà expérimenté l’année dernière . Cependant, avant de "soulever le capot" du langage de programmation
et de tenter de mettre en place nous même ce type abstrait de données nous allons un peu utiliser les dictionnaire en python, afin de nous remémorer leur fonctionnement.
Voici donc 2 exercices simples qui vous permettrons de vous remettre en tête le fonctionnement des dictionnaires en python.
Si vous manquez de bases...Tout est là.
Manipulations de base
-
définir le dictionnaire personne contenant les informations suivantes relatives à une personne :
- Nom : Dupuis
- Prénom : Jacque
- Age : 30
- corriger l'erreur dans le prénom et afficher le dictionnaire. La bonne valeur est "Jacques".
- afficher la liste des clés du dictionnaire.
- afficher la liste des valeurs du dictionnaire.
- afficher la liste des paires clé/valeur du dictionnaire.
- afficher la phrase : "Jacques Dupuis a 30 ans" en utilisant le dictionnaire.
Score au Scrabble
Le dictionnaire scrabble ci-dessous contient la valeur de chacune des lettres de l'alphabet au Scrabble :
scrabble = {"A":1,"B":3,"C":3,"D":2,"E":1,"F":4,"G":2,"H":4,"I":1,"J":8,"K":10,"L":1,"M":2,"N":1,"O":1,"P":3,"Q":8,"R":1,"S":1,"T":1,"U":1,"V":4,"W":10,"X":10,"Y":10,"Z":10}
- Écrire une fonction
scorequi calcule, en utilisant le dictionnaire scrabble, le score obtenu en plaçant un mot passé en argument à la fonction ( sans tenir compte des cases bonus : lettre compte-double, mot compte-triple, etc...) - tester la fonction avec quelques mots ( en utilisant éventuellement le module
doctest) :score('NSI') = 3 score('BONJOUR') = 16 score('KIWI') = 22 score('ANTICONSTITUTIONNELLEMENT') = 28
Primitives
Revenons maintenant au TAD "dictionnaire". Avant de l'implémenter étudions en détail ce TAD :
Pour "faire fonctionner" un dictionnaire, il faut disposer des opérations suivantes :
- créer un dictionnaire vide
- ajouter un élément dans le dictionnaire : on associe une nouvelle valeur à une nouvelle clé
- modifier un couple {clé:valeur} en remplaçant la valeur courante par une autre valeur (la clé restant identique)
- supprimer une clé (et donc la valeur qui lui est associée)
- rechercher une valeur à l'aide de la clé associée à cette valeur.
Comment coder un dictionnaire
Les dictionnaires peuvent être implémentées de différentes façons, comme vous avez déjà une bonne expérience de ce genre d'exercice nous n'aborderons qu'un seul codage :
Le codage grâce à un tableau indexé (une list python).
Cette solution de codage va consister à stocker dans un tableau des tableaux de deux éléments, le premier étant la clef et le seconde la valeur.
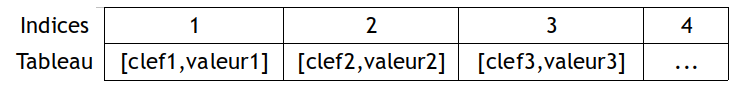
Vous devez coder les fonctions primitives suivantes ( pour une fois, pas de POO 😌...) :
creer_dico_vide():qui créé un dictionnaire videajouter(dico,clef,valeur):qui ajoute dans le dictionnaire dico la clefclefet lui associe la valeurvaleurla fonction renvoie le dictionnaire modifiémodif(dico,clef,valeur):qui modifie dans le dictionnaire dico la valeur associée à la clefclef. la fonction renvoie le dictionnaire modifiésupprimer(dico,clef):supprime dans le dictionnairedicola clefclefet la valeur associée.rechercher(dico,clef):recherche dans le dictionnairedicola clefclefet affiche la valeur associée. Si la clef n'est pas présente dans le dictionnaire, un message d'erreur est affiché
Rechercher dans un dictionnaire en "temps constant" (O(1)) !
Comme vous avez pu le voir en codant la fonction rechercher, il est nécessaire de parcourir le dictionnaire pour trouver une clef...Pourtant une des particularités des
dictionnaires (notamment en python), c'est de réaliser des recherches en "temps constant".
Cela signifie que le temps de recherche dans un dictionnaire n'augmente pas avec sa taille :
Il est aussi rapide de rechercher une clef dans un dictionnaire 100 éléments que dans un dictionnaire de 1 000 000 000 éléments !
Le principe
Une seule question : comment ça marche ?
Et bien contrairement à ce que nous avons fait dans la partie précédente, les clef ne sont pas rangées au hasard en mémoire, mais leur place est déterminée par la valeur de la clef elle-même.
Il existe ainsi une fonction de hashage qui associe à chaque clef une valeur entière qui déterminera la place des données stockées en mémoire.
Hashage d'un objet
Nous ne détaillerons pas les difficultés que l'on peut rencontrer pour construire une fonction de hashage, cependant on peut directement utiliser la fonction Python intégrée de base hash,
qui calcule la clé de hachage ( le hash ) d'un objet quelconque ( sauf les objets mutables ) et que Python utilise pour le stockage dans les dictionnaires :
Conclusion
Résumer ci-dessous les principales caractéristiques d'une "bonne" fonction de hachage :
Il est très difficile de construire une fonction de hashage fiable, car la diversité des clefs est potentiellement infinie et la fonction renvoie vers un nombre fini de valeurs.
Il faut à tout prix éviter les collisions, c'est à dire que deux clefs différentes donnent la même valeur.
Les fonctions de hashage sont utilisées dès que l'on a besoin d'une "empreinte digitale" d'un objet , qui permet d'identifier rapidement et facilement cet objet, dans des contextes comme le stockage efficace de données, ou la cybersécurité ( blockchain , cryptomonnaies, stockage de mots de passe, etc...)
D'ailleurs, un site ne pourra jamais vous redonner votre mot de passe au cas où vous l'avez perdu, la seule solution pour vous sera de le redéfinir.
En effet, il est très difficile (voire impossible) de retrouver une valeur à partir de son hash, c'est sur ce point que repose la sécurité des
mots de passe et de toute cryptographie en général.
Utilisation dans un dictionnaire
Le processus se fait en deux temps :
- Lors de l'insertion d'un couple (clef ,valeur), on applique à la clef la fonction de hashage :
hashage(clef)renvoie un entier qui détermine la place de la clef et de la valeur en mémoire. - Lors de la recherche d'une clef, on applique la fonction à la clef recherchée, et hashage(clef) nous donne directement l'emplacement mémoire ou retrouver les données : il n'est donc pas nécessaire de parcourir le dictionnaire , on a bien une recherche en O(1) !!!!
Application simplifiée
Il existe de très nombreux algorithmes de hachage, mais Nous ne pouvons pas mettre en œuvre une fonction de hashage complexe (et d'ailleurs ce n'est pas au programme de terminale); pour bien comprendre le fonctionnement de la recherche en O(1) dans un dictionnaire vous allez améliorer votre travail précédent pour simuler la recherche en temps constant dans un dictionnaire.
Un contexte simplifié
Nous allons nous intéresser à un dictionnaire dont les clefs ne peuvent être que des caractères de la table ASCII;
la taille du dictionnaire sera adonc limitée à 128 éléments maximum.
La fonction de hashage que nous allons utiliser est la fonction ord(). cette fonction renvoie le code ASCII correspondant à un caractère. Ainsi :
>>> ord('a')
97
Vous devez donc modifier les fonctions primitives suivantes :
creer_dico_vide():qui créé un dictionnaire vide contenant 128 éléments''ajouter(dico,clef,valeur):qui ajoute dans le dictionnaire dico la clefclefet lui associe la valeurvaleurla fonction renvoie le dictionnaire modifié. Le couple[clef,valeur]est insérer à l'indexord(clef)dans le tableaurechercher(dico,clef):recherche dans le dictionnairedicola clefclefet affiche la valeur associée. Si la clef n'est pas présente dans le dictionnaire, un message d'erreur est affiché. La recherche ne nécessite pas ici de boucle mais l'utilisation de la fonctionord()pour retrouver la place de la clef dans le tableau.
Comparaison des temps de recherche sur un tableau ou un dictionnaire en python
Nous allons maintenant faire quelques mesures de temps de recherche dans un tableau et dans un dictionnaire en utilisant les type construits existant dans python.
Voici la démarche que nous allons suivre :
- Construire par compréhension un dictionnaire et une liste comprenant des nombres aléatoires pris entre 0 et 1000
- Rechercher un élément ou une clef qui n'est pas présente dans chaque structure avec l'instruction
in(rechercher une valeur non présente nous garanti que l'on parcourra l'ensemble des structures de données) - Mesurer dans chaque cas le temps de recherche
La mesure de temps se fera grâce au module timeit qui permet de systématiser ce genre de tests. Voici le code de départ :
from random import *
from timeit import timeit
liste =[randint(0,1000) for i in range (1000000)]
dictionnaire={randint(0,1000): randint(0,1000) for i in range(1000000)}
print('liste : ',timeit(stmt='1001 in liste', globals=globals(), number=1000))
print('dictionnaire ',timeit(stmt='1001 in dictionnaire', globals=globals(), number=1000))
Les paramètres de la fonction timit sont les suivants :
- La chaîne de caractères
stmtcorrespond à l’instruction qui sera exécutée. - le paramètre
globalspermet d'utiliser les structures de données créées en dehors de la chaînestmtprécédente numberpermet d'exécuter l'instruction contenue dansstmtautant de fois que nécessaire (afin d'être sur de ne pas tomber sur un état particulier dans les processus au moment de la mesure du temps)
Vous devez maintenant :
- Exécuter le code ci-dessus et noter les temps obtenus
- Diviser la taille des structures de données par 10 et noter les temps obtenus
- Multiplier la taille des structures de données par 10 et noter les temps obtenus (attention, cela va prendre un peu de temps...vous pouvez même prévoir la durée approximative de votre attente)
- Expliquer pourquoi vos mesurent confirment que le temps de recherche dans une liste est en O(n) alors que dans un dictionnaire il est en O(1).