Nous allons considérer qu'une scierie reçoit des planches de longueur l entière.
La scierie découpe ces planches en morceaux de longueur également entière et les revend selon selon une grille tarifaire donnée :
longueur
0
1
2
3
4
5
6
7
8
9
10
prix
0
1
5
8
9
10
17
17
20
24
30
L'objectif est donc de découper chaque planche de façon optimale pour en tirer un prix maximum.
RésolutionS du problème
Afin de bien appréhender le problème répondez aux questions ci dessous ( approche "par force brute" : on étudie TOUTES les possibilités, afin de
déterminer la solution optimale.
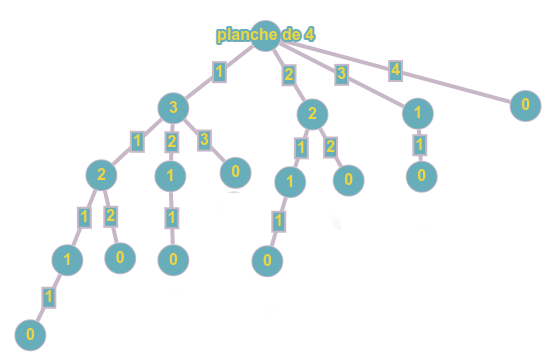
L'arbre ci-dessous présente toutes les découpes possibles d'une planche de longueur l = 4 :
chaque nœud correspond à la longueur restante de la planche après découpe;
sur chaque branche se trouve la valeur de la découpe à faire pour aboutir à cette longueur.
chaque feuille correspond donc à une longueur restante de 0...
1. Déterminer le revenu de chaque découpe possible.
3. En déduire la découpe optimale pour une planche de longueur 4.
Nous allons tenter de coder une fonction coupe_recurs prenant comme paramètres la longueur l de la planche et le tableau p
des prix, et qui renverra le revenu optimal que l'on peut tirer de la planche.
1. Si l'on décide de faire une première découpe de longueur i dans la planche,
quelle sera la longueur de la planche restante ?
2. Si l'on décide de faire une première découpe de longueur i dans la planche,
quel sera le revenu TOTAL correspondant à la partie coupée + la découpe du reste de la planche ?
3. L'idée de l'algorithme est alors de chercher récursivement, pour toutes les valeurs de i possibles, la valeur MAXIMALE du revenu total;
Proposer alors un algorithme récursif résolvant le problème :
Comme d'habitude, la solution récursive est "simple" à coder mais n'est pas très efficace...
Nous pouvons constater que nous sommes en présence d'un problème d'optimisation.
Nous allons maintenant chercher les sous problèmes et leurs chevauchements.
1. Dans l'arbre précédent, entourer les deux plus grands sous arbres identiques.
2. Quelle est la taille de cet arbre ?
3. De façon générale, si la planche a pour longueur n, quelle sera la taille de cet arbre ?
Nous allons maintenant tenter de construire un algorithme de résolution de ce problème grâce à la programmation dynamique, en se basant sur
le code récursif précédent
Adapter le code récursif en vous inspirant de la fonction fibo_memo vue précédemment : on utilise un tableau r pour mémoïser les
résultats intermédiaires.
le tableau r sera initialisé avec uniquement des 0 comme éléments.
La case r[i] du tableau r contiendra les revenus maximum pour une planche de longueur i
Le tableau r devra être transmis lors des appels récursifs
La réflexion issue de la programmation dynamique consiste, comme vous avez pu le voir jusque là, à supprimer des calculs redondants.
Nous avons vu qu'une solution consiste à mémoïser (stocker dans une structure de données adaptée) les calculs réalisés dans une fonction récursive.
Mais la programmation dynamique ne s'appuie pas nécessairement sur la programmation récursive !
On peut aussi tout simplement raisonner plus classiquement : de façon itérative.
Dans le cas du problème de la planche, on peut :
Calculer la découpe optimal pour une planche de 1 (facile), et stocker ce résultat
Calculer la découpe optimale pour une planche de 2, et stocker ce résultat
Calculer la découpe optimale pour une planche de 3, en s'aidant des deux résultats précédents, et stocker ce résultat
et ainsi de suite...
L'approche Bottom Up (ou du bas vers le haut, ou approche ascendante) est typiquement itérative.
L'approche Top Down (ou du haut vers le bas, ou approche descendante) est typiquement récursive.
Dans les deux cas on évite des calculs redondants en stockant chaque résultat intermédiaire.
Vous devez maintenant coder la fonction dyna_coupe_BU(n, p) permettant de résoudre le problème de façon dynamique en "Bottom-Up"
(d'où le BU).
Pour cela vous pouvez vous aider de l'ébauche algorithmique suivante :
l est la longueur de la planche
p est le tableau contenant les prix de chaque planche (p[i] est le prix de la planche de longueur i)
r est un tableau de longueur n+1 contenant initialement des 0
pour i de 1 à l:
pour j de 1 à i (on réalise une découpe de longueur j<=i)
chercher le maximum entre une découpe précédente et ce que rapporte la découpe de longueur j
stocker le revenu maximum d'une découpe i dans le tableau r
renvoyer le résultat recherché
Vous avez déjà vu ce problème en première lors de l'étude des algorithmes gloutons.
Présentation du problème
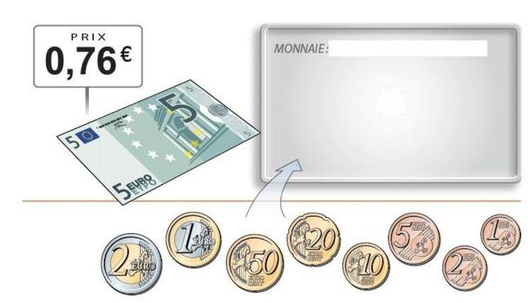
Le rendu de monnaie est un problème du quotidien; la question est la suivante :
vous devez rendre 4,24€ avec un système de pièces et de billets donnés en minimisant le nombre de pièce ou billets rendus.
Vous avez déjà résolu ce problème de nombreuses fois, en suivant un algorithme "instinctif".
Nous allons essayer de généraliser la résolution de ce problème à n'importe quelle somme (bien sûr), et à n'importe quel système de pièces
et de billets.
Le problème du rendu de monnaie c'est :
Rendre une somme donnée,
à partir d'un système de monnaie donné monnaie=[pièce1, pièce2, ..., billet1, billet2, ...]
Le problème consiste aussi bien sur à optimiser le rendu de monnaie en utilisant le moins de pièces ou de billets.
Rappels : la résolution gloutonne
Lorsque que vous avez résolu ce problème en jouant au marchand dans votre enfance, ou l'année dernière en Première, vous utilisez classiquement l'algorithme
glouton.
Un algorithme glouton est un algorithme qui fait un choix local optimal en espérant que cela conduise à une solution globale
optimale.
Concrètement dans le cas du rendu de monnaie, on choisit toujours la pièce ou le billet le plus grand possible, puis on soustrait
cette valeur à la somme à rendre et on recommence (en espérant rendre ainsi le moins de pièce ou de billets possibles !).
Dans le cas où le jeu de monnaie est le jeu européen actuel (le choix des valeurs des pièces et des billets n’a pas été fait au hasard),
la solution gloutonne est optimale.
Mais nous pouvons imaginer un système dans lequel le rendu de monnaie glouton n'est pas optimal;
par exemple si l'on veut rendre 6 dans un système composé de [1,3,4] :
La solution gloutonne nous donne 4+1+1 = 6;
Le problème étant très simple, on remarque que la solution optimale est plutôt 3+3 = 6...
Il existe des situations ou l'algorithme glouton n'aboutit pas du tout ! (essayez de rendre 8 de façon gloutonne avec un système monétaire
composé de [2,5,10])
Pour fixer les idées nous allons nous poser un problème simple :
nous allons imaginer que nous disposons d'un système de pièces limitées : 2 cts, 5 cts, 10 cts, 50 cts et 1 euro (100 cts)
1. Appliquer la méthode gloutonne pour une somme de 1€77cts.
2. Appliquer la méthode gloutonne pour une somme de 11cts.
3. Trouver une solution pour cette somme de 11cts.
Nous voyons donc que la solution gloutonne n'est pas forcément optimale, il peut même arriver qu'elle ne trouve pas de solution.
Exploration exhaustive
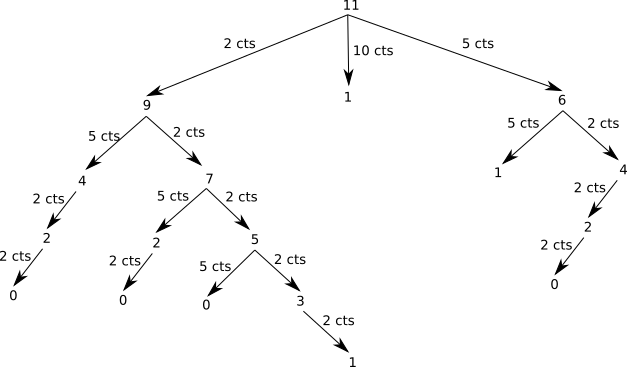
Si l'on explore toutes les possibilités de l'exemple précédent ( rendu de 11cts ), on arrive à l'arbre ci-dessous :
Une des solutions serait donc d'explorer de manière exhaustive toutes les branches de cet arbre, puis de sélectionner la ou les branches optimales.
La solution exhaustive est qualifiée de "force brute" car on parcourt toutes les solutions possibles avant de choisir la bonne.
Dans l'arbre des appels récursifs de l'exemple ci-dessus :
1. Identifier les branches de cet arbre qui n'aboutissent pas à une solution.
2. Identifier les branches de cet arbre qui aboutissent à une solution.
3. Identifier le nombre de pièces optimales dans cette situation.
Voici une fonction qui résout de façon récursive le problème du rendu de monnaie. La fonction renvoie le nombre de pièce optimal et non le rendu de
monnaie lui même.
Le principe est le suivant : si l'on choisit une pièce de valeur x dans le système monétaire, il faut ensuite rendre la monnaie
sur somme-x et choisir le nombre de pièce(s) optimal ( le plus petit ) dans chaque cas.
def rendu_rec(somme:float, systeme:list)->int:
if somme == 0:
return 0
else:
mini = 1000
for i in range(len(systeme)):
if systeme[i] <= somme:
nb = 1 + rendu_rec(somme-systeme[i], systeme)
if nb < mini:
mini = nb
return mini
systeme = [100, 50, 10, 5, 2]
print(rendu_rec(11, systeme))
Tester la fonction récursive sur une somme de 11cts avec le système de monnaie [100,50,10,5,2]
Tester la fonction récursive sur les sommes 177cts et 289 cts avec le système de monnaie [100,50,10,5,2]. Quel problème rencontrez vous ?
Nous allons maintenant tenter d'optimiser cette fonction récursive grâce à la programmation dynamique.
Si l'on continue à analyser, on peut trouver dans cet arbre, des chevauchements de sous problèmes :
On se retrouve 2 fois à calculer comment rendre 4cts dans cette situation. on retrouve donc les conditions de la programmation dynamique avec :
Des sous problèmes à combiner pour résoudre un programme plus important
Des sous problèmes identiques (qui se "chevauchent")
Coder une fonction fonction en python rendu_dyna, qui prend en argument une somme à rendre et un tableau de systeme de monnaie.
Cette fonction doit utiliser un tableau f contenant des 0, et de longueur somme+1
Cette fonction doit ensuite renvoyer un appel à rendu_dyna_memo(somme, systeme, f)
Comme vous l'avez compris, nous venons de créer le tableau de mémoïsation f.
Par la suite, ce tableau contiendra, à un indice i, le nombre de pièces à rendre pour la somme i.
Il nous reste à coder la fonction dyna_rendu_memo(somme, systeme, f) en s'appuyant sur la fonction récursive pure précédente.
Reprenez le code de votre fonction récursive et modifiez là comme indiqué ci-dessous :
Avant de commencer le remplissage récursif du tableau f, la fonction va vérifier si f[somme] n'existe pas déjà dans le tableau.
Tester la nouvelle fonction sur une somme de 11cts avec le système de monnaie [100,50,10,5,2]
Tester la nouvelle fonction sur les sommes 177cts et 289 cts avec le système de monnaie [100,50,10,5,2]. Rencontrez vous le même problème que précédemment ?
Si vous avez suivi cette démarche pas à pas, vous voyez maintenant l'amélioration algorithmique qu'il existe entre une fonction récursive "simple" et une fonction récursive avec
mémoïsation (programmation dynamique de haut en bas).
Question subsidiaire : pouvez-vous améliorer votre code pour qu'il renvoie aussi la liste des pièces à rendre pour la solution optimale ?
Promenade dans un tableau de tableaux : projet Euler
Présentation du problème
Ce problème classique de l'informatique est extrait du site https://projecteuler.net.
Le problème consiste à trouver le "chemin de poids le plus faible" dans une matrice, appelé "plus court chemin".
Les règles sont les suivantes :
On commence à la case en haut à gauche de la matrice (ici 131), on termine dans la case en bas à droite (ici 331).
On ne se déplace dans le tableau que vers le bas et vers la droite.
A chaque pas on ajoute la valeur de la case correspondante.
L'objectif est de trouver le chemin le plus court en respectant ces règles.
Dans le tableau précédent, ce parcours est indiqué en rouge, et vaut : 131+201+96+342+746+422+121+37+331=2427.
Un algorithme glouton donnerait-il la solution optimale ?
Exploration exhaustive
Comme précédemment, nous allons chercher la relation de récurrence qui permet d'explorer toutes les possibilités de chemin afin de trouver celui de
poids le plus petit.
L'idée est de déterminer le chemin de poids minimal pour arriver à une case donnée tab[i][j], en fonction des cases depuis lesquelles on
vient dans le parcours.
Attention, plusieurs cas sont à considérer selon la situation d'une case dans le tableau : il y a deux cas particuliers, les cases tout
à gauche ( première colonne ) ou tout en haut ( première ligne ) du tableau
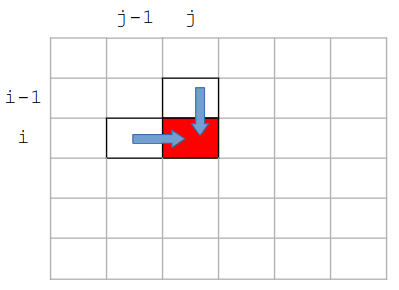
1. Pour une case quelconque tab[i][j] dans le tableau, il y a deux possibilités pour y arriver :
- soit depuis la case juste au dessus : tab[i-1][j]
- soit depuis celle juste à sa gauche : tab[i][j-1]
Comment calcule-t-on alors le poids du chemin depuis chacune de ces deux cases jusqu'à la case tab[i][j] ?
Comment choisir la meilleure solution ?
2. Pour une case située sur la première ligne tab[0][j], il n'y a là qu'une seule possibilité;
donner alors la relation de calcul du chemin depuis cette case
3. Même question pour une case sur la première colonne (tab[i][0])
4. Indiquer quel est le cas de base, et le résultat alors renvoyé.
Écrire alors la fonction récursive qui implémente cet algorithme; vous pouvez la tester sur la matrice donnée en exemple ( attention à l'appel de
la fonction : quelles valeurs doivent avoir les arguments de i et j ? )
Mais qu'en serait-il avec cette matrice de 80x80 ??? (N'essayez même pas...)
Nous allons tenter de résoudre ce problème grâce à la programmation dynamique.
Vous trouverez ci-dessous un peu de code permettant de transférer le fichier texte fourni
dans une liste de listes ( penser à enregistrer ce fichier sur votre PC, puis à le charger dans l'éditeur )
with open('matrix.txt','r') as f:
matrix = [ligne.split(",") for ligne in f]
matrix = [[int(matrix[i][j]) for j in range(len(matrix[0]))] for i in range(len(matrix))]
Approche top-bottom ( mémoïsation )
En vous inspirant des exemples traités précédemment, implémenter une version dynamique par mémoïsation de la fonction de recherche du chemin de poids
minimal. Vous utiliserez ici un tableau de tableauxphi de mêmes dimensions que la matrice, et ne contenant initialement que des
valeurs -1 ( par exemple ); ce tableau contiendra, si il a déjà été calculé, le poids du plus court chemin jusqu'à la case [i][j].
Tester votre code avec la matrice donnée en exemple, puis avec la matrice 80x80 : le résultat est alors 427 337.
def euler_memo(m: list[list])->int:
"""Cette fonction crée le tableau de mémoïsation, puis appelle la fonction de calcul,
et renvoie le résultat"""
pass
def euler_memo_calcul(m: list[list], i: int, j: int, phi: list[list])->int:
pass
m = [[131, 673, 234, 103, 18],
[201, 96, 342, 965, 150],
[630, 803, 746, 422, 111],
[537, 699, 497, 121, 956],
[805, 732, 524, 37, 331]]
Dans cette approche, on remplit le tableau phidepuis la première case (m[0][0]), en calculant pour chaque case le poids du plus court chemin pour
arriver jusqu'ici.
Attention là aussi aux cas particuliers à gérer ( première ligne et première colonne).
Le résultat sera obtenu en renvoyant la valeur stockée dans la dernière case du tableau de tableaux phi.
def euler_BU(m: list[list])->int:
"""Cette fonction crée le tableau, puis appelle la fonction de calcul,
et renvoie le résultat"""
pass
def euler_BU_calcul(m: list[list], i: int, j: int, phi: list[list])->int:
pass
m = [[131, 673, 234, 103, 18],
[201, 96, 342, 965, 150],
[630, 803, 746, 422, 111],
[537, 699, 497, 121, 956],
[805, 732, 524, 37, 331]]
Comme nous l'avons constaté, la programmation dynamique peut permettre d'améliorer la résolution de nombreux problèmes. Cette technique est très adaptée en particulier aux problèmes d'optimisation, c'est à dire à la recherche d'un maximum ou d'un minimum au sens large.
Présentation du problème
On considère le problème suivant :
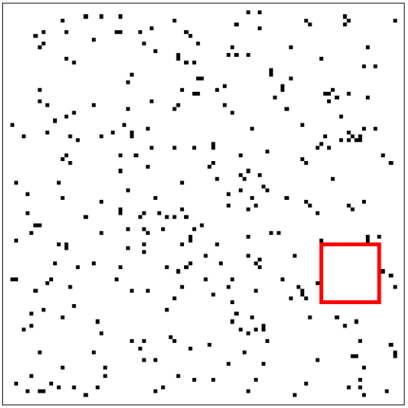
Une image blanche de dimensions nxn contient aléatoirement répartis des pixels noirs. Nous allons chercher dans ce carré le plus grand carré blanc possible.
Ce problème simplifié peut trouver de nombreuses applications :
lors de l'optimisation de l'agencement de chaînes de montage dans un hangar industriel
lors de l'analyse d'un territoire et de sa couverture par des antennes 4G par exemple
...
Identification du sous problème
L'idée de base va donc être de parcourir toute l'image et de chercher le plus grand carré blanc. Mais il faut réfléchir un peu...Et déterminer un sous problème plus simple:
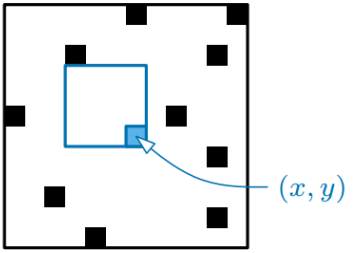
Nous allons donc chercher pour chaque pixel de coordonnées (x,y) la taille du plus grand carré blanc dont le pixel (x,y) est le coin en bas à droite.
A priori, il faut donc partir de ce pixel et vérifier si tous les carrés de dimensions (i,i) (dont le coin en haut à gauche a pour coordonnées ((x+i,y+i))sont blancs, dès que l'on trouve un pixel noir, on arrête et on note les dimensions du carré précédent.
Dans ce cas, pour tester un carré de dimensions mxm il faut vérifier m2 pixels.
Cependant on peut encore simplifier le problème grâce à une observation importante :
Pour vérifier si un carré mxm est bien blanc, il suffit de vérifier si :
le pixel en bas à droite est bien blanc
les trois carrés de dimensions (m-1)x(m-1) représentés ci-dessous sont bien blancs
Codage de la recherche du plus grand carré blanc
Fonction récursive
Nous allons tout d'abord tenter de coder une version récursive simple de la fonction qui détermine la taille du plus grand carré blanc en partant d'un pixel de coordonnées (x,y) placé en bas à droite de ce carré : plusGrdCarreBlanc(x,y,img).
1. Que doit renvoyer la fonction si le pixel de coordonnées (x,y) est noir ?
2. Que doit renvoyer la fonction si x=0 ou si y=0 ?
3. Quels sont les coordonnées des pixels "en bas à droite" des trois carrés présentés ci-dessus ?
4. En déduire la relation de récursivité (ou appeler le professeur...) permettant de trouver plusGrdCarreBlanc(x,y,img) grâce à trois appels
récursifs et à une fonction de recherche de minimum.
Coder et tester la fonction plusGrdCarreBlanc(x,y,img)
Parcourir le tableau de tableaux pour chercher le plus grand carré blanc
Pour vous aider dans vos tests je vous propose une image de test de dimensions 10x10 :
Fonction récursive avec mémoïsation : programmation dynamique de haut en bas
Si votre fonction récursive fonctionne correctement sur une image de dimensions 10x10, cela ne sera peut être pas le cas sur une image "réelle de 3000x2000 pixels !
Nous allons donc faire appel à la programmation dynamique et la mémoïsation.
Adapter le code récursif précédent en vos inspirant du travail réalisé sur les fonctions de calcul de la suite de Fibonacci ou sur le découpage d'un planche.
Dans ces fonctions, le tableau memo contiendra dans la case [x][y] le plus grand carré blanc en partant du pixel en bas à droite.
Le tableau memo
devra être transmis lors des appels récursifs
Il sera nécessaire de construire deux fonctions, dont une ne fera que construire le tableau de tableaux memo rempli initialement de None, et appeler ensuite la fonction récursive elle même.
Une fois la fonction testé sur des cases choisies, parcourir le tableau de tableaux pour chercher le plus grand carré blanc
La distance d'édition (ou distance de Levenstein ou distance d'Ulam) est un algorithme permettant de comparer deux chaînes de caractères ch1 et ch2.
Cette distance est définie comme le nombre d'opérations minimum qui permet de passer de la première chaîne à la seconde en ne considérant que trois seules opérations possibles
pour passer d'une chaîne à l'autre :
Suppression d'une lettre de la chaîne ch1,
Insertion d'une lettre "parasite",
Remplacement d'une lettre de la chaîne ch1.
Par exemple :
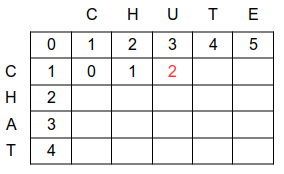
la distance entre CHAT et CHUT est de 1 : ( remplacement d'une lettre par une autre )
la distance entre CHAT et CHUTE et de 2 ( remplacement d'une lettre + ajout d'une autre )
la distance entre CHAT et CHOYAT est aussi de 2 ( insertion de 2 lettres )
Cet algorithme est utilisé de manière intensive dans les situations où il faut évaluer les différences entre un mot ou un texte, et un autre :
comparaison des différences entre deux fichiers ( commande Unix diff )
comparaison d'un mot avec une liste de mots dans un dictionnaire pour proposer des corrections ( correcteur orthographique )
reconnaissance de caractères ( OCR )
...
Analyse
On suppose ici que toutes les modifications ont un coût ( c'est à dire qu'elles augmentent la distance ) de 1.
L'idée de l'algorithme dans sa version "naïve" est de déterminer les valeurs de distance entre toutes les sous-chaînes de ch1 et ch2.
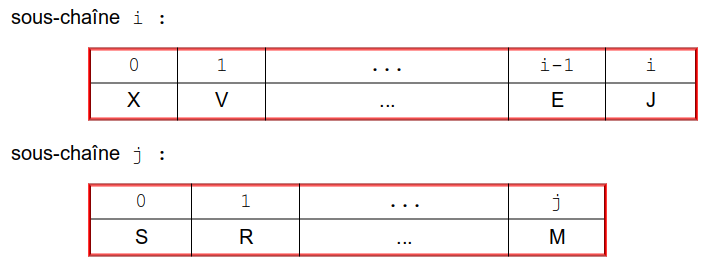
On considère deux chaînes ch1 et ch2, de longueurs égales ou non.
on note d(i, j) la distance entre la sous-chaîne de ch1 d'indice 0 à i ( = "sous-chaîne i" ), et la sous-chaîne de ch2
d'indices 0 à j ( = "sous-chaîne j" ) :
Par convention, i == -1 ou j == -1 signifie que l'on considère une chaîne vide.
On aura donc :
d(-1, -1) = 0 ( la distance entre deux chaînes vides est la même qu'entre deux chaînes identiques, à savoir 0 ).
d(-1, j) = j+1( la distance entre une chaîne vide et une chaîne contenant j+1 caractères ( les indices commencent à 0 ! ) est égale à j+1
d(i, -1) = i+1 (idem )
On compare les sous-chaînes de ch1 et ch2 pour 0 ⩽ i < len(ch1) et 0 ⩽ j < len(ch2).
Pour chaque comparaison, d(i, j) sera alors le minimum entre les valeurs de distance après chaque modification possible pour passer de la sous-chaîne i à la sous-chaîne j.
Analysons les cas possibles :
Insertion ou ajout d'une lettre : dans ce cas, la sous-chaîne j a une lettre en plus que la sous-chaîne i, et la distance est augmentée de 1 par rapport à
la distance calculée à l'appel précédent, c'est à dire la distance entre deux chaînes de longueur :i et j-1 :
→ la relation de récurrence est alors : d(i, j) = 1 + d(i, j-1)
Suppression d'une lettre : dans ce cas, la sous-chaîne j a au contraire une lettre en moins que la sous-chaîne i :
Établir la relation de récurrence qui lie alors d(i, j) à la valeur de d calculée à l'appel précédent.
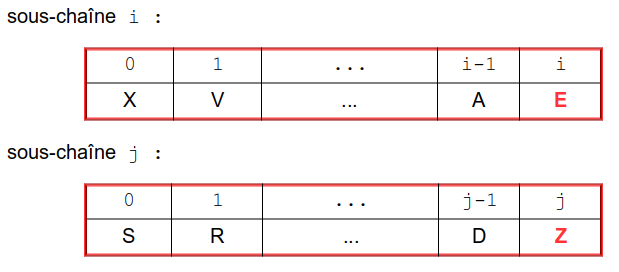
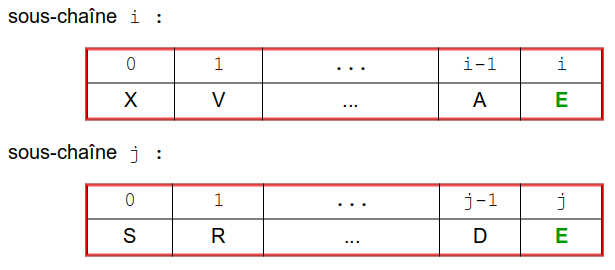
Remplacement d'une lettre ou pas de modification : dans ces deux cas, les deux sous-chaînes ont la même taille, mais :
la distance augmente de 1 dans le cas du remplacement de la lettre à l'indice i de ch1 par la lettre à l'indice j de ch2 :
la distance n'augmente pas si ces deux lettres sont identiques :
Établir alors la relation de récurrence qui donne d(i, j) dans ces deux situations.
le cas général sera le minimum entre les 3 valeurs calculées; quels sont alors les deux cas de base de la récursion ?
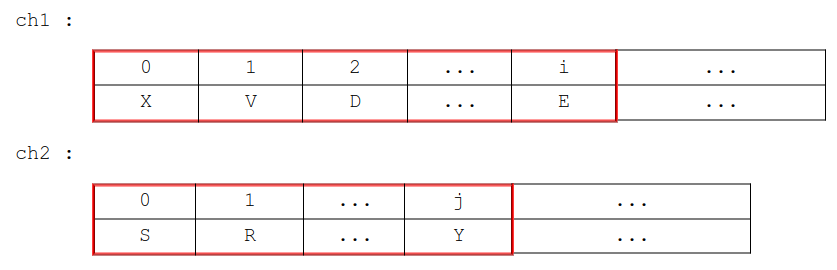
Compléter la fonction dist_lev_rec récursive ci-dessous qui prend en paramètre deux indices i et j, et qui renvoie
la distance de Levenshtein entre deux chaînes ch1 ( paramètre i ) et ch2 ( paramètre j ).
Pour simplifier la signature de la fonction ( il faudrait sinon aussi les passer en paramètres...), les chaînes ch1 et ch2 sont stockées dans deux variables définies dans le programme principal, et donc accessibles
en lecture seule depuis la fonction.
Vérifier la correction de la fonction avec les exemples suivants, et d'autres !
On montre que la complexité de l'algorithme naïf est O(3(m+n)) ( où m et n sont les tailles des deux chaînes ) ! Pour comparer deux mots, c'est encore envisageable, mais pour comparer deux textes, cela devient inutilisable...
Essayez par exemple ( ou pas.. ) avec les deux phrases suivantes :
ch1 = "les sanglots longs des violons de l'automne blessent mon coeur d'une langueur monotone."
ch2 = "les sangliers lents des violents de l'atome blasent mon corps d'une longueur manhattan."
On doit trouver 21...
Approche top-bottom
L'idée sera donc bien sûr de faire appel à la mémoïsation pour stocker les résultats déjà calculés à un appel récursif précédent, et de les réutiliser au besoin.
Ici, il faudra stocker ces résultats dans un dictionnaire, dont les clés seront les tuples (i, j) et les valeurs, celles des d(i, j) correspondant.
Comment initialiser ce dictionnaire ? Comment savoir si un résultat avait déjà été calculé ?
Écrire une fonction dist_lev_TB qui utilise la mémoïsation pour améliorer la complexité de l'algorithme :
Tester cette nouvelle version, notamment avec l'exemple des deux phrases ci-dessus !
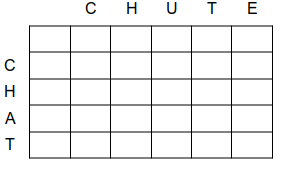
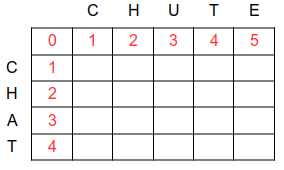
Dans cette approche itérative, on remplit un tableau de tableaux, de taille (m+1)*(n+1), dont les lignes correspondent aux caractères de ch1, et les colonnes à ceux de ch2.
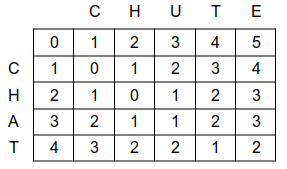
Chaque case (i, j) contient la valeur d(i, j) ( exemple de la distance entre 'CHAT' et 'CHUTE' ) :
La première ligne et la première colonne correspondent chacune à une sous-chaîne vide.
Le remplissage du tableau se fait de la manière suivante :
La première case (0, 0) correspond à la distance entre une sous-chaîne vide et une sous-chaîne-chaîne vide : elle est donc de 0.
Sur la première colonne, on trouve les distances entre une sous-chaîne de ch1 de 1 caractère, puis 2, puis 3, etc...et une sous-chaîne vide : la distance augmente donc régulièrement de 1 sur cette colonne.
Idem pour la première ligne, qui contient les distances entre une sous-chaîne de ch2 de 1 caractère, puis 2, puis 3, etc...et une sous-chaîne vide.
On peut donc remplir sans calcul la première ligne et la première colonne du tableau :
pour la ligne suivante, on compare la sous-chaîne i 'C' avec la sous-chaîne j 'C' ( distance de 0 ), puis 'C' avec 'CH' ( 1 ajout ), puis 'C' avec 'CHU' (2 ajouts ), etc... :
et ainsi de suite pour les lignes suivantes :
Pour chaque case (i, j), on calcule le coût minimal des insertions, suppressions et substitutions en "provenance" des cases voisines.
D'après l'étude précédente, et en vous aidant de la relation de récurrence établie précédemment, établir la relation générale qui permet de calculer la distance d(i, j) en fonction des valeurs des cases voisines.
en fin de remplissage du tableau, où se trouve la valeur de la distance minimale entre les deux chaînes ch1 et ch2 ?
On fera particulièrement attention à la manière d'adresser un caractère dans les chaînes ch1 et ch2...
def dist_lev_BU(ch1: str, ch2: str)->int:
m = len(ch1)
n = len(ch2)
# Création du tableau
pass
# Remplissage de la première ligne et de la première colonne du tableau :
pass
# Parcours du tableau et calcul des valeurs de distance pour chaque case :
pass
# Renvoi de la distance minimale
pass