Projet OCR
La reconnaissance optique de caractères ( OCR = Optical Character Regognition ) est le procédé qui consiste, à partir de l'image d'une information écrite sur un support analogique ( livre, journal,...), d'en extraire le texte et de le transformer en un fichier directement lisible par un système informatique.
C'est un domaine de recherche très actif afin de trouver les algorithmes les plus fiables qui permettent de faire sans erreur cette conversion, et de gros progrès ont été faits ces dernières années.
Nous verrons dans ce projet une méthode très simple de reconnaissance de caractères dans des images; ce n'est pas cette méthode qui est utilisée en réalité, mais elle est simple et donne des résultats satisfaisants; de plus, cela va vous permettre de rafraîchir vos connaissances en programmation Python, sur les variables, les boucles, les tableaux, etc...!
Dans tout ce projet, les mots en gras désignent des notions ou des concepts importants à bien connaître et maîtriser.
Bien lire les en-têtes de fonction et notamment les annotations de type pour identifier le type des paramètres et celui des valeurs renvoyées.
Ce travail s'inspire d'un tutoriel du site Zeste de Savoir.
Principe
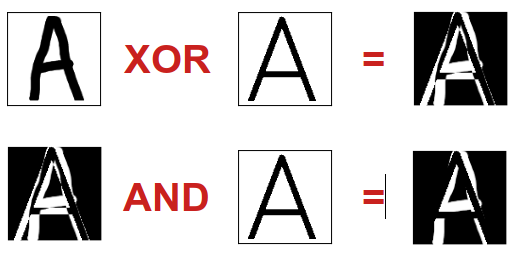
L'idée est de "comparer" bit à bit l'image d'un caractère manuscrit à identifier avec des images "témoins" de caractères connus, en réalisant des opérations booléennes ( = logiques ) entre les bits de chacune de ces images.
Plus précisément, on réalise deux opérations successives :
- premièrement, une opération de OU EXCLUSIF ( XOR ) entre les bits de l'image du caractère à identifier et ceux de l'image de chaque caractère témoin
- ensuite, une opération de ET ( AND ) entre le résultat obtenu précédemment et ceux de l'image du caractère témoin.
A l'issue de ce traitement, plus l'image du chiffre témoin a été "effacée" ( donc plus elle est noire ), et plus le caractère témoin est proche du caractère à identifier, ce qui permet alors de déterminer ce dernier.
Si tout cela n'est pas très clair, c'est peut-être l'occasion de revenir sur la représentation des nombres en mémoire d'un ordinateur.
- rappeler les définitions d'un bit et d'un octet.
- les images que vous allez utiliser sont codées en niveaux de gris : la luminosité de chaque pixel est codé par un unique octet.
- Combien de valeurs de luminosité possibles permet ce codage ?
- sachant que chaque image a une définition de 100 x 100 pixels, donner la taille du fichier image non-compressé correspondant ( le format utilisé ici est le PNG, qui est en réalité compressé )
- avec un codage en couleurs RVB, chaque pixel serait codé par un triplet d'octets, un pour chaque couleur primaire Rouge, Vert ou Bleu.
- combien de couleurs possibles aurait permis ce codage ?
- déterminer là-aussi la taille du fichier non-compressé.
- on utilise la numération binaire ( = en base 2 ) pour représenter un nombre en mémoire d'un ordinateur.
Après avoir revu le principe de cette numération, donner la représentation binaire sur 8 bits des nombres décimaux010,25510et21910. - A l'inverse, donner l'équivalent en base 10 du nombre binaire :
100011102. - On rappelle ci-dessous les tables de vérité du OU EXCLUSIF et du ET :
A B A ET B A OU EXCLUSIF B 0 0 0 0 1 0 0 1 0 1 0 1 1 1 1 0 Donnez en base 10 le résultat des opérations booléennes :
21910 XOR 14210et21910 AND 14210
Les ressources pour ce projet
Dans cette archive, vous trouverez les ressources suivantes :
- un ensemble de 26 fichiers images au format PNG (
A.pngàZ.png) correspondant aux caractères témoins de l'alphabet ( en majuscules ) - 7 fichiers images (
1.pngà7.png) correspondant aux caractères manuscrits à identifier - un module nommé
images.pyqui vous permettra :- d'ouvrir un fichier image et de récupérer les valeurs de ses pixels sous forme d'un tableau de tableaux ( = matrice ) d'entiers sur 8 bits
- d'enregistrer un fichier image à partir du tableau de tableaux des valeurs de ses pixels
Ce module devra être préalablement importé au début de votre script; pour son utilisation, à vous de lire les docstring des fonctions incluses dans ce module...
Pour commencer, quelques manipulations de fichiers que l'on pourra avec profit réaliser en ligne de commande :
- télécharger l'archive, et décompresser-la dans dans votre répertoire personnel; un nouveau dossier nommé
Projet OCRa été créé. - ouvrir l'éditeur Pyzo, et créer dans le dossier précédent un script nommé
ocr.py
Pour prendre ensuite en main les ressources :
- écrire au début du script l'instruction qui permet d'importer le module
images.py - après avoir étudié la docstring des fonctions et analysé la manière d'ouvrir un fichier image, écrire une instruction qui permet de stocker dans une variable le tableau de tableaux des valeurs de pixels d'une image quelconque.
- pour bien se rappeler comment "fonctionne" un tableau de tableaux, écrire les instructions qui permettent d'afficher :
- la première ligne du tableau de tableaux, puis sa 6ème ligne
- la valeur du pixel situé à la 3ème colonne et à la 8ème ligne
- le nombre de lignes du tableau de tableaux
- le nombre de colonnes du tableau de tableaux
Pré-traitement
Une phase de "pré-traitement" des caractères à identifier est à réaliser : ceux-ci sont en effet codés en niveaux de gris, alors que les caractères témoins sont en deux couleurs ( noir et blanc ).
Vous allez donc écrire un code qui permette de transformer une images en niveaux de gris en une image en noir et blanc.
Le principe est assez simple :
- on parcourt chaque pixel de l'image ( donc chaque élément du tableau de tableaux )
- si la valeur du pixel courant est inférieure à une valeur donnée appelée seuil, alors on remplace cette valeur par la valeur 0 ( = noir )
- si cette valeur est supérieure au seuil, alors on la remplace par la valeur 255 ( = blanc )
Détermination du seuil
Tout le problème est de déterminer la valeur du seuil à utiliser; en pratique, on utilisera la moyenne des valeurs de tous les pixels de l'image.
La détermination de cette moyenne fera l'objet de l'écriture de votre première fonction.
Toutes les fonctions que vous allez écrire devront bien sûr être complétées avec leur docstring.
Écrire une fonction seuil() qui :
- prend comme paramètre le tableau de tableaux des valeurs de pixels d'une image
- renvoie un entier, valeur moyenne des pixels de l'image.
def seuil(data: list)->int:
.....
.....
Un petit rappel pour le parcours des éléments d'un tableau de tableaux : on utilisera ici un parcours par indice afin de pouvoir modifier la valeur de chaque élément; le parcours se fera à l'aide de deux boucles imbriquées, l'une pour les "lignes", l'autre pour les "colonnes" de chaque ligne :
pour i variant de 0 à l'indice de la dernière ligne:
pour j variant de 0 à l'indice de la dernière colonne :
.....
.....
Faire, bien entendu, les tests unitaires nécessaires à la vérification du bon fonctionnement de la fonction, éventuellement en utilisant le module doctest; par exemple,
la fonction doit renvoyer 179 pour l'image 1.png, et 195 pour l'image 5.png.
Passage au noir et blanc
Écrire une fonction noir_blanc() qui :
- prend comme paramètre le tableau de tableaux des valeurs des pixels d'une image
- renvoie le tableau de tableaux des valeurs modifiées des pixels pour une conversion en noir et blanc
def noir_blanc(data: list)->list:
.....
.....
Cette fonction fera appel à la fonction seuil() pour la détermination de la valeur du seuil à utiliser.
Vous écrirez les conditions à évaluer pour transformer un pixel donné en un pixel soit noir ( 0 ) soit blanc ( 255 ).
Pour tester cette fonction, vous pouvez afficher le résultat qu'elle renvoie, et vérifier que le tableau de tableaux ne contient plus que des 0 et des 255.
Analyse
Maintenant que toutes les images sont au même format, vous allez pouvoir vous intéresser au traitement d'un caractère en vue de son identification.
Une fonction de traitement
Et voila le cœur du problème...l'idée est de parcourir en même temps les pixels des deux images, ceux du caractère à identifier et ceux d'un caractère témoin, et d'effectuer les opérations booléennes entre les valeurs de ces pixels comme décrit ci-dessus.
Dans un premier temps, vous allez écrire une fonction traitement() qui :
- prend comme paramètres deux tableaux de tableaux : le premier correspondant à un caractère à identifier, le deuxième à un caractère témoin
- renvoie le tableau de tableaux des pixels après les opérations logiques décrites au premier paragraphe
def traitement(data1: list, data2: list)->list:
.....
.....
Les opérations logiques se feront directement sur les octets des tableaux de tableaux. On pourra enchaîner directement les deux opérations booléennes XOR et AND
Du fait que les tableaux sont des objets mutables, il sera impératif de travailler sur une copie faite au préalable des tableaux afin de ne pas modifier ces derniers.
En Python, l'opérateur booléen AND correspond au symbole &; l'opérateur XOR au symbole ^.
Pour tester la fonction, vous pouvez enregistrer l'image obtenue à partir du résultat renvoyée par la fonction, et vérifier qu'elle a bien le même aspect que celui décrit au premier paragraphe.
Une fonction d'identification
Et pour terminer, la fonction qui va permettre de déterminer à quel caractère un fichier image donné correspond.
Écrire une fonction ocr() qui :
- prend comme paramètre le nom d'un fichier image d'un caractère à identifier
- renvoie la lettre correspondant à cette image
def ocr(nom: str)->str:
.....
.....
Il y a beaucoup à faire dans cette fonction...en voila un algorithme succinct pour vous guider un peu :
- ouvrir le ficher image du caractère à identifier et récupérer le tableau de tableaux de ses pixels
- transformer ce tableau de tableaux en noir et blanc
- Ensuite, pour chaque caractère de l'alphabet, donc pour chaque fichier image de
A.pngàZ.png:- appeler la fonction de traitement entre le tableau de tableaux du caractère à identifier et le caractère courant de l'alphabet
- déterminer le nombre de pixels blancs dans l'image témoin d'origine, puis le nombre de pixels blancs qui restent à l'issue du traitement, et en déduire le pourcentage de pixels blancs ayant disparu ( plus ce pourcentage est grand, plus l'image a été "effacée", et donc plus le caractère témoin est proche de celui à identifier.)
- ranger ce pourcentage dans un dictionnaire, dont la clé est la lettre courante de l'alphabet, et la valeur le pourcentage de pixels blancs restants
- une fois tout l'alphabet traité, rechercher dans le dictionnaire le pourcentage maximal de pixels blancs ayant disparu : la clé correspondant à cette valeur permettra de d'en déduire le caractère correspondant à ce maximum, et donc le caractère identifié.
- renvoyer le caractère identifié
Si on appelle b1 le nombre de pixels blancs dans une image témoin d'origine, et b2 le nombre de pixels blancs restant à l'issue du traitement de cette image, alors le pourcentage de
pixels blancs ayant disparu est donné par la relation : p = 100*(1 - b2/b1)
Voila une ébauche de fonction qui pourra vous guider dans ce travail :
def ocr(lettre: list)->str:
'''Reconnaissance d'une lettre manuscrite par comparaison avec les lettres témoins de l'alphabet.
ENTREEE :
lettre : tableau des pixels de la lettre manuscrite
SORTIE :
lettre_identifiee : le caractère ( str ) identifié.
'''
dico = {} # dictionnaire des scores de chaque comparaison
lettre = noir_blanc(lettre) # pré-traitement du caractère à identifier
# traitement
alphabet = [chr(i) for i in range(65,91)] # création par compréhension d'un tableau contenant les lettres de l'alphabet
for temoin in alphabet:
lettre_temoin = get_data_from_image(temoin + '.png') # récupération du tableau des pixels du caractère témoin correspondant à 'temoin'
resultat = traitement(lettre, lettre_temoin) # opérations logiques entre les pixels des deux caractères
# comptage des pixels blancs dans l'image témoin, puis dans le résultat du traitement
pass
# calcul du pourcentage de pixels blancs ayant disparu après traitement
pass
# placement de ce pourcentage dans le dictionnaire comme valeur associée au caractère témoin courant
pass
# recherche du maximum dans les valeurs du dictionnaire
pass
# renvoi du caractère identifié
return lettre_identifiee
OCR sur plusieurs images
Bon, il ne reste pas grand-chose à faire; il serait bien d'optimiser la reconnaissance des caractères dans les 7 images; de façon à ce que le script nous donne directement la chaîne de caractères constituée de ces caractères
Dans le programme principal de votre script, écrire les instructions qui permettront de traiter successivement et automatiquement les 7 images, et de construire une chaîne de caractères qui contiendra les caractères identifiés dans ces images.
L'exécution de votre script affichera donc le mot VAUGELAS 😉.
Conclusion
La méthode présentée ici est loin d'être optimale, et nécessite que les caractères à identifier soient déjà bien formés pour être correctement reconnus.
Globalement, deux grand principes sont utilisés dans le cadre de la reconnaissance optique de caractères :
- le filtrage par motif ( pattern matching ), où le caractère à reconnaître est comparé à un jeu de caractères témoins; c'est le cas de la méthode que nous avons utilisée ici, mais il existe d'autres algorithmes beaucoup plus performant.
- l'apprentissage automatique ( machine learning ), où des algorithmes d'intelligence artificielle sont utilisés; un algorithme qui donne de bons résultats est notamment l'algorithme des k plus proches voisins ( KNN = k-nearest neighbors ) vu en Première.