Applications des SD
En application de toutes les structures données linéaires que vous venez de découvrir, nous vous proposons une série de problèmes mettant en œuvre l'une de ces structures (pile, file, liste, dictionnaire...).
Pour résoudre le problème qui vous sera attribué, vous devrez déterminer la structure la mieux adaptée à votre problème. Rappelez vous de la citation de Linus Torvald :
“Bad programmers worry about the code. Good programmers worry about data structures and their relationships.”
Temps prévu :
- 3 séances de préparation/résolution du problème/écriture du code, de la page HTML + 1 séance de présentation orale.
- du travail en autonomie à la maison sera nécessaire pour compléter/finaliser votre projet
Le choix du projet n'est pas à la carte : demander au professeur celui qui vous a été attribué...
Votre travail devra se structurer de la manière suivante :
- Découverte du problème et prises de notes
- Travail sur papier (30 min) pour tester le problème, choisir la structure de données, faire des schémas etc...
- Codage de votre problème en utilisant les différentes classes ou fonctions que vous avez réalisées pendant cette séquence de cours.
Une fois que tout cela "tourne" cela ne sera pas fini. En effet, nous allons commencer notre travail d’entraînement au grand oral. Vous devrez donc préparer :
- Une ( ou plusieurs... ) pages web présentant :
- Les grandes lignes de votre problème
- Les grandes lignes de votre résolution de problème, en justifiant notamment le choix de la structure de données retenu pour cette résolution, l'algorithme utilisé, etc...
- votre code commenté, qui servira de correction pour vos camarades
- tout document utile, image, JavaScript si ça vous tente 😊 ,...
Cette/ces page(s) sera/seront ensuite intégrée(s) sur le site pour consultation publique.
Pour la mise en forme de la page, vous pouvez récupérer cette archive, dans laquelle vous trouverez une ébauche de fichier HTML, le fichier CSS du site, et les explications pour intégrer dans votre page quelques éléments particuliers, notamment votre code pour qu'il soit formaté de la même manière que sur le site.
Vous pourrez bien entendu écrire vos propres règles de style....
- une intervention orale de 5 minutes face à vos camarades reprenant les grandes lignes de votre problème et des principes de sa résolution. Il n'est pas nécessaire d'entrer dans les détails du code, mais il faudra mettre en avant le choix de la structure de donnée que vous aurez choisie.
Liste de contacts efficace
Les listes de contacts personnelles peuvent atteindre des volumes de données importantes (par exemple, mon "Google contact" personnel compte aujourd'hui 1674 fiches différentes !)
Les listes de contacts de petites ou moyennes entreprises peuvent être facilement 10 ou 100 fois plus importante. Il devient essentiel d'avoir des outils de recherche efficaces.
Vous devez mettre en œuvre une liste de contacts, contenant des fiches simplifiées à deux champs :
- Nom Prénom
- Numéro de téléphone
Vous prévoirez ensuite les fonctionnalités suivantes :
- Ajouter un contact
- Enlever un contact
- Rechercher un contact
La recherche des contacts devra être optimisée en O(1) (en temps constant).
Poste de contrôle

Un poste de contrôle est alimenté en pièces toutes les 7 minutes. Ces pièces sont de quatre types qui nécessitent respectivement 4, 6, 8 et 9 minutes pour être contrôlés.
Les quatre types de pièces ont la même probabilité d'apparaître au poste de contrôle.
Simuler le fonctionnement du poste de contrôle pendant 1 heure, puis 80 heures.
Le programme devra afficher à chaque minute :
- Le nombre de pièces en attente de contrôle
- La durée de séjour des pièces dans le poste de contrôle.
Attente au restaurant
Un restaurant de 50 tables à 2 couverts ouvre ses portes pendant 4 heures chaque soir.
L’intervalle de temps entre l’arrivée de deux groupes de clients est d’environ 2 minutes.
Les groupes sont constitués aléatoirement de 2 à 6 convives avec des fréquences identiques.
Les tables peuvent être rassemblées pour les groupes de plus de 2 personnes. Lorsqu’un groupe arrive, il attend que des tables en nombre suffisant soient libres.
Une fois assis, le groupe reste pendant une durée aléatoirement comprise entre 60 et 120 minutes.
Simuler le fonctionnement du restaurant pendant une soirée :
- Afficher le nombre de client en attente et le nombre de clients assis à chaque minute
- Afficher le nombre de clients servis lors d’un service et nombre moyen de clients par table
Fonction zéros
Un des problèmes classique de l'informatique est la recherche de sous-chaînes dans une suite de caractères. Nous verrons cette année à ce propos L'algorithme de Boyer-Moore.
Une simplification de ce problème peut être la recherche de séries particulière.
Écrire une fonction zeros() qui prend en paramètre un tableau t et qui renvoie le plus grand nombre de zéros consécutifs dans le tableau .
Par exemple : zeros([0, 1, 1, 2, 0, 0, 0, 5, 0, 0]) renvoie 3.
Fonction "suite croissante"
Un des problèmes classique de l'informatique est la recherche de sous-chaînes dans une suite de caractères. Nous verrons cette année à ce propos L'algorithme de Boyer-Moore.
Une simplification de ce problème peut être la recherche de séries particulière.
Écrire une fonction suite_croissante() qui prend en paramètre un tableau t et qui renvoie la longueur de la plus grande suite croissante dans le tableau.
Par exemple : suite_croissante([5, 9, 7, 0, 1, 2, 3, 0, 8, 9, 10, 5, 2]) renvoie 4 ( longueur de la suite 0, 1, 2, 3 ).
En amélioration, on pourra faire en sorte que la fonction renvoie également cette suite la plus longue ( sous forme de tableau par exemple, ou de tuple ).
Tri avec une pile
Comme vous le savez l'avantage de la pile par rapport à la liste est la faible complexité de ses primitives empiler et dépiler. Nous allons donc nous pencher sur la possibilité de réaliser un tri grâce à une pile.
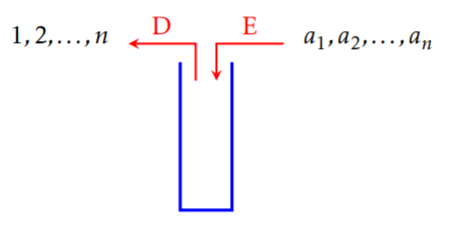
Malheureusement, toutes les listes ne sont pas triables avec une seule pile.
Si on note D et E les opérations d'empilage et de dépilage, la liste [4, 1, 3, 2] peut être triée par la séquence EEDEEDDD.
- Parmi les listes suivantes, lesquelles peuvent être triées par une pile ?
- (2,4,1,3)
- (3,1,2,5,4)
- (4,5,3,7,2,1,6)
- Une fois que vous avez compris l'algorithme grâce à ces exemples, codez la fonction
tri_en_pile()qui prend comme argument une liste et qui renvoie une liste triée si cela est possible.
Problème de Flavius Josèphe
Un problème mathématique connu est le problème de Josèphe.
L'histoire est la suivante :
"Des soldats juifs, cernés par des soldats romains, sont obligés de former un cercle. Un premier soldat est choisi au hasard et est exécuté, le troisième à sa gauche est ensuite exécuté.
Tant qu'il y a des soldats, la sélection continue. Le but est de trouver à quel endroit doit se tenir un soldat pour être le dernier et donc être épargné.
Flavius Josèphe, peu enthousiaste à l'idée de mourir, parvint à trouver l'endroit où se tenir.
- Dans un premier temps, cherchez, sur papier la solution à ce problème dans le cas où il y a 7 soldats en cercle initialement.
- Ensuite, codez une fonction
flavius(), qui prend comme paramètres :- n = le nombre de soldats en cercle
- p = l'endroit où l'on choisit le soldat à exécuter ( le pième à gauche ).
La notation polonaise inverse
La notation polonaise inverse (NPI) (en anglais RPN pour Reverse Polish Notation) permet d'écrire de façon non ambiguë les formules arithmétiques sans utiliser de parenthèses.
Par exemple, l’expression « 3 × (4 + 7) » peut s'écrire en NPI sous la forme : « 4 7 + 3 × ».
Bien que cette notation ait certains avantages, elle n'a été adoptée que par les calculatrices de la marque HP. On l'utilise cependant dans certains domaines comme dans les vols spatiaux, où elle présente un gain de temps non négligeable ainsi qu'un risque moindre d'erreur (pas de risque de parenthèse manquante ou décalée).
Cette page présente un émulateur de calculatrice HP-35 utilisant cette notation.
Un calcul en NPI
On parcourt l'expression depuis son début. On stocke les opérandes ( = les valeurs sur lesquelles on fait les calculs ) dans l'ordre où ils apparaissent.
Quand un opérateur de calcul ( +, *, - ou / ) apparaît, on récupère les deux opérandes immédiatement disponibles, et on stocke le résultat de leur calcul à leur place.
On continue le parcours de l'expression avec ce résultat intermédiaire.
Lorsque l'expression a été entièrement parcourue, le calcul est terminé et le résultat est la seule valeur stockée.
Exemple :
Calcul du résultat de l'expression : 3 10 2 - *
| Entrée | Stockage des données |
|---|---|
| 3 | 3 |
| 10 | 3 10 |
| 2 | 3 10 2 |
| - | 3 8 |
| * | 24 |
→ résultat = 24. L'expression est donc équivalente à : ( 10 - 2 ) x 3.
Réflexion préalable
- Déterminer la structure de données la mieux adaptée à cette situation.
- Que signifie, dans le vocabulaire associé à la SD choisie, la phrase "On stocke les opérandes dans l'ordre où ils apparaissent" ?
- Que signifie de même "on récupère les deux opérandes immédiatement disponibles" ?
Fonction de calcul en NPI
Écrire une fonction NPI() qui :
- prend en paramètre une chaîne contenant les opérandes et opérateurs d'une expression en NPI
- renvoie le résultat du calcul en utilisant la structure de données sélectionnée précédemment.
>>> exp = "3 10 2 - *"
>>> print(NPI(exp))
24
>>>
Indication : La méthode chaine.split(' ') permet de séparer les mots d'une chaîne selon le caractère séparateur "espace", et renvoie le tableau de ces mots.
La fonction devra de plus indiquer si l'expression était correctement écrite.
De la musique avec des nombres : l'algorithme Karplus-Strong
Le son numérique
La musique digitale représente les sons comme une succession régulière dans le temps d'échantillons, c'est à dire de valeurs entières discrètes représentant l'intensité du son à des instants très rapprochées.
La durée entre deux échantillons successifs, constante, est appelée période d'échantillonnage; plus elle est petite, plus le son numérique se rapproche d'un son analogique qui est lui, continu
dans le temps; mais la quantité d'échantillons pour une même durée de son augmente alors, et donc la taille du fichier son résultant également.
Cependant, un principe fondamental du numérique est que la fréquence d'échantillonnage doit être au moins le double de la fréquence du son à numériser si l'on veut que le son soit "fidèle" à son
équivalent analogique.
Un compromis est donc à faire entre qualité sonore et taille du fichier; en pratique, des fréquences ( = inverse de la période ) d’échantillonnage de 44kHz ( = 44 ⨯ 106 échantillons par seconde ),
48 kHz voire 96 kHz sont courantes actuellement.
Le deuxième facteur qui influe sur la qualité d'un son numérique est la quantification, qui donne le nombre de valeurs entières possibles pour coder un échantillon : plus ce nombre est grand, plus la numérisation sera "précise". Actuellement, des quantifications sur 16 voire 24 bits sont courantes.
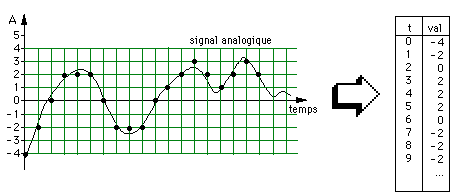
La synthèse sonore numérique
De très nombreuses façons de synthétiser des sons ont été envisagées, dans un premier temps pour reproduire des instruments réels, puis avec l'avènement des synthétiseurs, pour créer des sonorités qui n'existaient pas auparavant.
Avec la synthèse numérique du son par ordinateur, il est maintenant possible de créer directement les échantillons en leur donnant la valeur que l'on veut, afin de reproduire n'importe quel sonorité.
L'algorithme Karplus-Strong
Bien que très simple sur le papier et à programmer, il permet de synthétiser des sons qui se rapprochent d'instruments à cordes pincées ( guitare, harpe, ...) ou de percussions extrêmement réalistes.
Cet algorithme se présente ainsi :
- on commence par remplir un tableau ( appelée "buffer" ou tampon ) avec des échantillons aléatoires ( = de valeur tirée au hasard ) : on obtient ainsi un court bruit blanc, que l'algorithme va ensuite traiter ( de plus, ce bruit blanc ressemble au bruit généré par le "pluck" d'un mediator sur une corde....)
- on joue ensuite "en boucle" le buffer mais en le modifiant à chaque instant, en remplaçant chaque échantillon par la moyenne de deux échantillons successifs : on simule ainsi la décroissance naturelle d'un son de corde vibrante, mais en plus le timbre du son est tout à fait proche de celui naturellement émis par une telle corde.
Le bruit blanc à l'origine du son...
Et c'est tout !! Assez incroyablement, le son produit est vraiment comparable à celui d'une corde de guitare ( pour obtenir un son de percussion, c'est un peu plus compliqué ).
Cet algorithme permet de créer un son en "temps réel" mais vous vous en servirez pour construire des fichiers au format .WAV destinés à être lus ensuite.
Pour cela, vous aurez à votre disposition ce module qui permet d'enregistrer un fichier son en fournissant le tableau des échantillons. Bien lire la docstring des fonctions
de ce module pour comprendre leur fonctionnement.
Simulation de cordes pincées
Vous allez écrire un script Python qui utilise l’algorithme K-S pour créer le tableau des échantillons qui permettra ensuite d'écrire des fichiers .WAV de sons de guitare de fréquence donnée; voici quelques indications :
Fréquence d'échantillonnage
Pour des raisons sur lesquelles nous ne nous étendrons pas, la fréquence d'échantillonnage doit être assez élevée pour obtenir des résultats corrects, et ce d'autant plus que la fréquence du son à créer est élevée ( sons aigus ); vous prendrez donc : fech = 20000 Hz.
Taille du buffer
La durée de l'ensemble des échantillons du buffer doit correspondre à la période T du son à créer.
On appelle f la fréquence du son à créer, et fech la fréquence d'échantillonnage; on montre que le nombre N d'échantillons du buffer est donnée par la relation :
N = fech / f.
Pour obtenir des résultats corrects, vous créerez des sons de fréquence f ≈ 200 - 1000 Hz
Application de l'algorithme
Le principe d'application de l'algorithme K-S est le suivant :
- à chaque itération, on calcule la moyenne du premier et du deuxième échantillons du buffer
- on ajoute à la fin du buffer la valeur de cette moyenne
- on retire le premier échantillon du buffer, et on l'ajoute au tableau des échantillons qui constitueront le son final ( le buffer garde donc toujours la même taille )
- on continue ainsi de "balayer" le buffer; le tableau des échantillons du son final se crée ainsi peu à peu, échantillon après échantillon.
- on s'arrête quand on a obtenu assez d'échantillons pour obtenir un son de durée donnée

Améliorations éventuelles
On se rend vite compte que le son s'amortit d'autant plus vite que sa fréquence est élevée, ce qui est d'ailleurs cohérent avec une vraie guitare.
Cependant, on peut améliorer la sonorité des sons aigus de la manière suivante : au lieu de calculer la moyenne de deux échantillons successifs, on en calcule la moyenne pondérée par un coefficient ( noté α ), compris entre 0 et 1 :
- l'échantillon d'index 0 aura un "poids" égal à α
- l'échantillon d'index 1 aura un "poids" égal à 1 - α
Ceci marche mieux avec des sons de haute fréquence ( avec des sons graves, le son sonne alors trop "métallique"...).
Faites varier α entre 0,5 et 0,9.
on rappelle que la moyenne pondérée de deux valeurs A et B, de poids respectifs α et β, est donnée par : m = ( 1 α + β ).(α.a + β.b)
Simulation de percussions
L'algorithme reste sensiblement le même, mais la façon de créer les données change : un nouvel échantillon n'est plus toujours égal à la moyenne de deux échantillons successifs; il ne lui est égal qu'avec une probabilité de 50%, et sinon il est égal à l'opposé de cette moyenne. Autrement dit, l'échantillon a une chance sur deux d'être égal à la moyenne, et une chance sur deux d'être égal à son opposé...
Vous allez donc modifier le script précédent pour appliquer ce principe.
Il va falloir se servir du générateur de nombres pseudo-aléatoires de Python pour simuler des probabilités.
Le principe est le suivant : on tire un nombre au hasard entre 0 et 100; si ce nombre est inférieur à 50, alors la probabilité est vérifiée, et sinon elle n'est pas vérifiée ( ce qui correspond bien à 50%, soit
une chance sur deux...)
Attention, dans le cas de percussions, la taille du buffer ( qui dépend de la "fréquence" f du son ) ne conditionne plus la hauteur du son mais la durée de l'extinction du son : plus le buffer est petit ( donc f est grande ), et plus le son est "étouffé" rapidement.
C'est alors la valeur de f qui permet de reproduire différentes percussions, il ne faudra pas hésiter à expérimenter !